Marko Oja
Marko helps customers to understand the endless possibilities of technology and to transform innovative ideas into technical solutions. Agile methods and process development are close to his heart.
Microsoft Fabric is one of the hottest technologies right now, and it has been since its announcement, as many data professionals can see the potential behind it. The progress of Fabric’s deployment features are improving constantly and getting closer to an enterprise-grade setup. Partially because of the newly gained maturity, many organizations are evaluating if it’s time to hop on the Fabric train. If you are one of those lucky people doing the evaluation, you might be interested in the deployment models and considerations related to MS Fabric. This article is by no means a complete or comprehensive list but rather a sneak peek into deployment models and considerations related to MS Fabric and what you might encounter while designing your Fabric architecture and implementation patterns.
Let’s start with what we actually want to accomplish. Because if you are doing a lightweight proof-of-concept or a simple self-service analytics setup, these things might not suit your use case or be of interest. However, if you are implementing an enterprise-grade data platform, you must have different environments. This means that in a typical setup, you have designated and separated development, testing, and production environments, or even a few more. From a conceptual perspective, it is sufficient to have two separate environments like development and testing, where actual data pipelines, structures, and most importantly the data itself are not shared between these environments.
In Fabric, this could mean using domains to divide things, but at minimum, it means that we should have different storage locations and executable pipelines separated. Of course, if we add Power BI into the mix, then semantic models and reports are environment-specific as well. The most important argument for multiple environments is that we do not want to break production integration or reports by deploying something that isn’t in a working order. For this reason, we develop in dev, perform integration and system testing in test, and use and operate the actual system in prod.
In Fabric, there are two core ways of doing deployments to enable use of multiple environments. If you are familiar with Power BI deployment pipelines, then you already know about the first one. The second way of doing deployment is through GIT integration, which, in addition to enabling you to push your implementation to version control, also makes it possible to pull changes from version control into the workspaces. Complementing these two methods are Fabric APIs that can also be used to perform deployment-related tasks.
With deployment pipelines, you have a pipeline that defines deployment steps from one environment to the next. Consider that 'dev' is your starting point, where you deploy to 'test', and from 'test' to 'production'. These deployment pipelines allow you to configure deployable objects, such as setting parameters for semantic models and configuring lake house connections for notebooks that are deployed from one workspace to another. You can build a quite well-working deployment process for Power BI models and reports using the deployment pipelines as they are now.
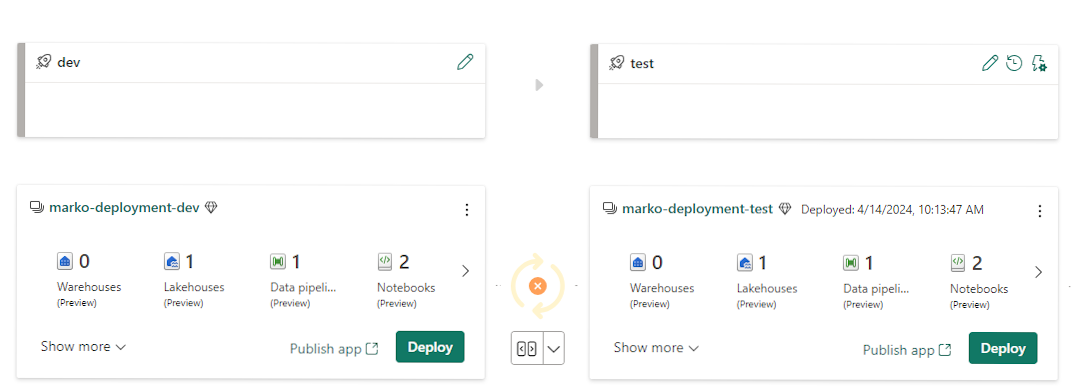
The second option for deployments is GIT integration, but this requires some imagination. We can still follow the same basic principle of moving implementation from dev to test to prod. However, instead of using deployment pipelines in Fabric, we push our recent version into a GIT repository in Azure DevOps and use pull requests from the dev branch to test and prod branches. For this to take effect on the Fabric side, we also need to link our workspaces to the corresponding branches. Once we update the branch in DevOps, we receive a visual reminder in the workspace of incoming changes, and then we can simply pull the latest version in.

 Many deployment-related features are already in the preview phase. Some
Many deployment-related features are already in the preview phase. Some
of these new features are: support of (for
example) pipelines and notebooks in
deployment pipelines, GIT Integration and new
Fabric API.
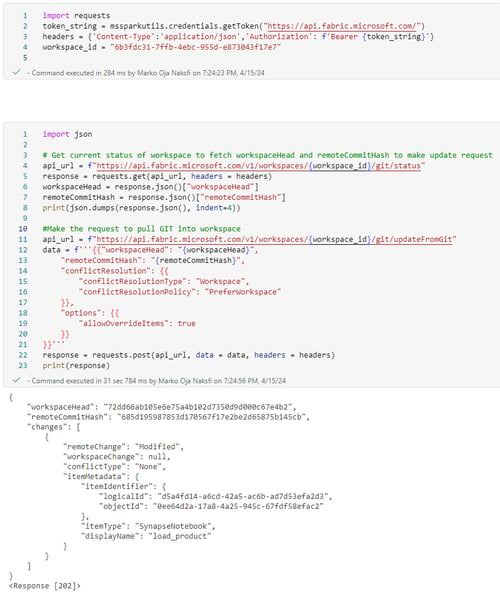
The new Fabric API is also crucial in enabling the GIT-based deployment model. This is because you need a way to trigger the pull process from version control into Fabric. You can do this manually, but that’s not really a feasible approach when you have multiple workspaces that you want to deploy as one system update. By using the Fabric API, you can easily perform the update with code/script of your choice. This involves authenticating using an OAUTH token and then requesting an update from the defined GIT repository. The best part is that this process is relatively easy to add as part of a standard DevOps deployment pipeline once service principal support comes available.
Another new option worth mentioning is the SQL database project support for the Fabric warehouses ( SQL-projects support for warehouses in Microsoft Fabric).
It's worth noting that there isn’t official support for GIT integration or deployment pipelines at the moment, but they are on their way. At this point, all structures inside a warehouse have been undeployable, so SQL Project support is a significant step forward.
Last but not least, is the lakehouse. I believe it’s a bit of a stretch to say it is on the supported list of deployable objects, as there isn’t any way to even get GIT integration for the table definitions. That being said, it’s not uncommon for there to be a lack of schema management for delta tables available, at least not out of the box. And by these standards, the Fabric lakehouse is aligned with other similar solutions.
There are a few tricks you can use to support lake house deployment. One of them is to design and build your pipelines in such a way that they will create the tables when they are not available initially. This is actually quite easy, as actual pipelines do it automatically, and for notebooks, you can use code like this:
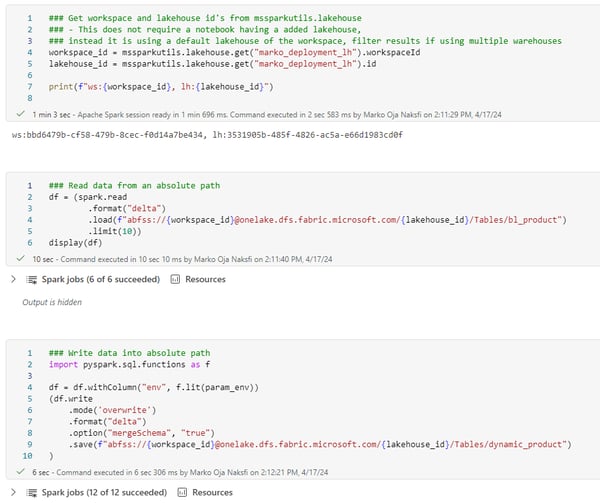
Additionally, writing the data directly into an absolute path makes it possible to write easily deployable notebooks that don’t require configuration at deployment time. For example, this notebook doesn’t require the lakehouse to be set. Instead, we can use default information, such as the default of the workspace in which the notebook is executed, like workspace and lakehouse IDs. This information is obtainable using the functions of the mssparkutils-package. I recommend becoming familiar with this package if you are interested or planning to use notebooks in your Fabric solution.
We can expect multiple new features to become available in the upcoming two quarters. I predict that by the end of 2024, deployment capabilities might reach true production maturity. What’s most encouraging for me personally is the clear effort that Microsoft is putting into Fabric's deployment model; it's evident they understand the importance of these critical features for large enterprises.
The latest added capabilities, including the APIs, have pushed Fabric beyond an important threshold, and in my opinion, it's a good time to start evaluating the use of Fabric for production-critical projects. For now, you might have to design your load patterns in such a way that deployment becomes somewhat easier. Additionally, you will need to do some work on the Azure DevOps side to ensure everything works smoothly.
Currently, we still have to balance between full automation and partial manual deployment. However, the scales are tipping, so there are a few things I would look for in future releases. These updates will hopefully include an interface to maintain connections, official DevOps modules, and broader GIT integration support.
I am looking forward to seeing the currently available preview features reaching general availability and can’t wait to witness all the improvements coming in the near future.