Marko Oja
Data-arkkitehti, joka auttaa asiakasta ymmärtämään tekniikan mahdollisuudet ja muuntaa innovatiiviset ideat teknisiksi ratkaisuiksi. Ketterät kehitysmenetelmät ja kehitystyötä tukevat prosessit ovat lähellä Markon sydäntä.
Aikaisemmissa blogipostauksissa esiteltiin Databricksin arkkitehtuuria, kehitystä, tehokkuutta ja kustannuksia sekä visualisointien avustamaa analysointia. Tässä blogisarjan viimeisessä osassa esittelen mielestäni tärkeimmät huomiot toteutuksesta teknisellä tasolla. Pyrin ennen kaikkea nostamaan esille ne hankalammin Googlella löydettävät yksityiskohdat, jotka mahdollistavat sarjassa esitellyn arkkitehtuurillisen toteutuksen.
Ensimmäinen nice to know -knoppi tulee, kun haluat käyttää Data Lake Store Gen 2:sta Databricksin lähteenä. Yhdistäminen tapahtuu Service Principalilla. Käytettävälle applikaatiolle tulee antaa Storage Account Contributor (tai Reader) -oikeudet lähderesurssiin. Huomiona siis, että pelkkä Contributor-oikeus ei ole riittävä. Tämän jälkeen containerin mounttaus on suoraviivainen toimenpide, josta löytyy googlaamalla hyvät ohjeet. Käytännössä ajetaan yksi Python-skripti.
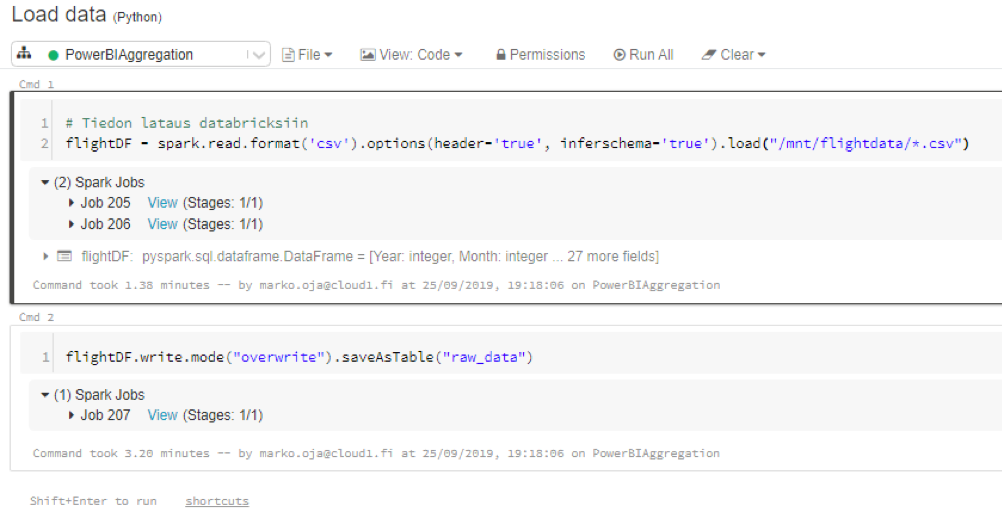
Lähdedata oli esimerkissä CSV-muodossa, eikä vaatinut suurempaa siivoamista. Tiedot ladattiin data frameen, joka tallennettiin klusteriin tauluksi. Tällöin tiedot kirjoittuvat fyysisesti klusterin levyjärjestelmään.
Toteutuksessa käytin Spark SQL:ää tiedon aggregoimiseen ja tallentamiseen. SQL kielenä tarjoaa selkeitä etuja yksinkertaisella syntaksillaan tämänkaltaisten työvaiheiden suorittamiseksi. Verrattuna vaikka Pythoniin, jossa vastaavan tuloksen saamiseksi olisi joutunut kirjoittamaan ainakin omasta mielestäni huomattavasti paljon sekavamman koodinpätkän. INSERT INTO & SELECT FROM -yhdistelmästä on vaikea enää selkeydessä parantaa.

Klusterin asetuksia muutettaessa joutui aggregoinnin skriptiin lisäämään vielä "REFRESH TABLE"-komennon raw_data -taululle. Tämä saattaa olla hyvä best practise, jos vastaavaa joutuu tekemään tuotantototeutuksiin, ja haluaa hyödyntää SQL-syntaksia. Olettaen tietysti, ettei pysty ensimmäisellä kerralla arvioimaan lopullista klusterin kokoonpanoa nappiin.
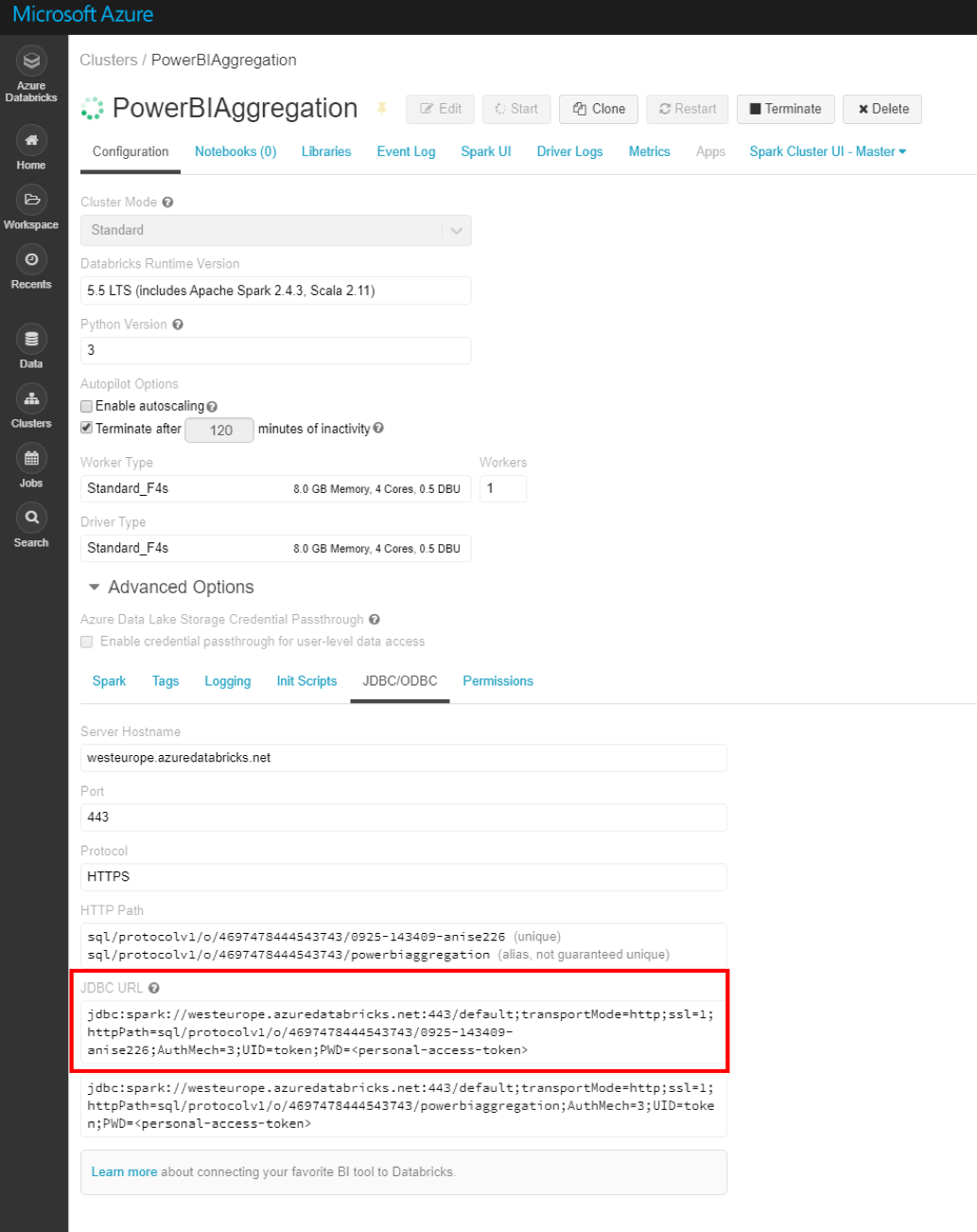
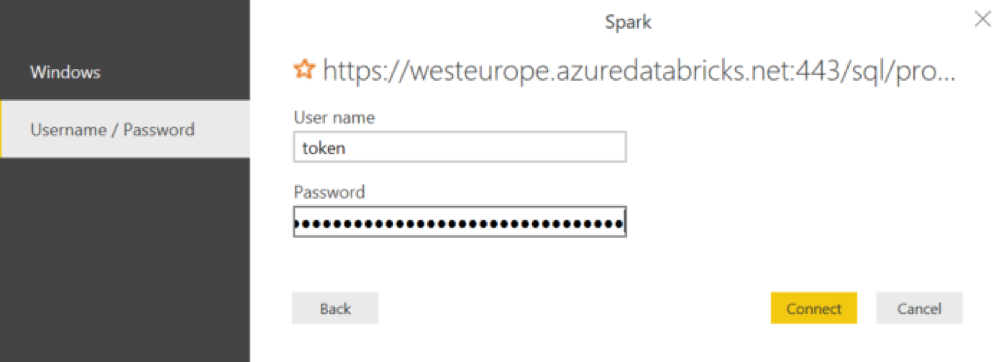
Klusterin Advanced Options -kohdan alta löytyy JDBC/ODBC -välilehti, jonka alta taas löytyy JDBC URL. Tuota urlia hieman muokkaamalla (kuva) saadaan aikaiseksi Power BI:tä varten tarvittava connection string. Yhteystyypiksi Power BI:ssä valitaan spark ja käyttäjätunnukseksi sana "token". Salasanaksi luodaan Databricksissä Access Token, joka löytyy User Settingsien takaa. Tämän jälkeen luodut taulut löytyvät Power BI:stä ongelmitta, ja ne voi liittää normaaliin tapaan tietomalliksi.

Lue myös:
Databricksin hyödyntäminen big data -analytiikassa (1/5) – Arkkitehtuuri
Databricksin hyödyntäminen big data -analytiikassa (2/5) – Kehitys
Databricksin hyödyntäminen big data -analytiikassa (3/5) – Tehokkuus ja kustannukset
Databricksin hyödyntäminen big data -analytiikassa (4/5) – Analysointi
(Blog in English coming soon...)