Marko Oja
Data-arkkitehti, joka auttaa asiakasta ymmärtämään tekniikan mahdollisuudet ja muuntaa innovatiiviset ideat teknisiksi ratkaisuiksi. Ketterät kehitysmenetelmät ja kehitystyötä tukevat prosessit ovat lähellä Markon sydäntä.
Pyrin yleensä kirjoittamaan sellaisten aiheiden ympäriltä, joiden soveltaminen käytäntöön saattaa olla osaksi teknologian usvan peitossa, mutta joiden tavoite on yleensä hyvinkin selkeä, jopa käsin kosketeltava.
Data governance, eli siis tiedon hallintamallit ja prosessit, eivät ole lainkaan suoraviivaisia, yksiselitteisiä tai tarkoin rajattuja.
Uudet ideologiat monesti vielä vähemmän. Asiat, joissa ihmiset vaikuttavat huomattavasti tekniikkaa enemmän, harvoin ovat. Tämän kertainen aiheeni, Data Mesh, sisältää teknistä arkkitehtuuria, mutta vielä enemmän se keskittyy hallinta- ja toimintamalleihin.
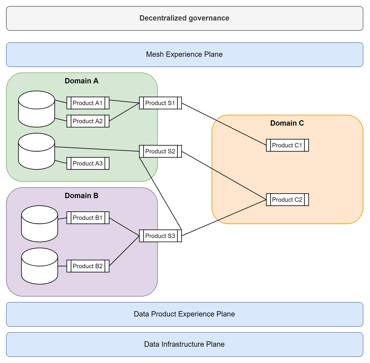
Alkuperäisestihän Data Mesh on Zhamak Dehghanin esittelemä, paremman termin puutteessa, paradigma tiedon hallinnan ja arkkitehtuurin luomiseen suuren yrityksen datatarpeisiin. Kirjassaan (Data Mesh - Delivering Data-Driven Value as Scale) Dehghani avaa konseptia, joka ulottuu lähdejärjestelmistä lähtien aina kehittyneisiin ML pohjaisiin data tuotteisiin asti. Data Mesh sisältää tiedon hallinnan lisäksi, myös arkkitehtuurimallin ja joitakin toteutuskonsepteja käytännön tueksi.
Jos pyrkisin nostamaan kaikki kiinnostavat kulmat Dehghanin kirjasta, joutuisin kirjoittamaan varmastikin kymmeniä sivuja. Tästä syystä olen valinnut muutamia aiheita, jotka itse koin tärkeiksi ja joiden esittelemiseksi ei tarvitse sukeltaa syvälle arkkitehtuuriin tai teknologiaan.
Data tulisi olla helposti kaikkien saatavilla
Kuten näimme data lake hypen alkuvaiheen toteutuksista, tallennetusta tiedosta ei ole iloa, mikäli siihen ei pääse käsiksi tai sitä ei löydä. Ilmiötä on kutsuttu siinä kontekstissa data swamp:iksi. Mutta Data Mesh:in mukaan kyse ole ainoastaan löydettävyydestä ja tavoitettavuudesta, vaan tiedon pitäisi olla myös sellaisessa muodossa rakenteellisesti, ja ehkäpä myös teknisesti, että sitä pystytään helposti hyödyntämään. Myönnettäköön, että teknistä implikaatiota joutuu kirjaa lukiessa jonkin verran hakemaan rivien välistä. Kuitenkin jos tietoa tarjoillaan hyvin teknisesti vaihtelevissa muodoissa, niin aiheuttaa se tunnetusti ongelmia.
Yksi syy miksi API:t ovat tulleet niin suosituksi tiedon jakelussa, on nimenomaan niiden kyky standardoida teknistä toteutusmallia.
Rest-tyyppiset API:t eivät kuitenkaan sovellu kovin hyvin analyyttisille dataseteille tai striimidatalle, joten muitakin jakelukanavia, nimen omaan tietoalustalle tyypillisille käyttötapauksille, tarvitaan.
Datan saavutettavuus, sen kaikissa ulottuvuuksissa, on mielestäni kuitenkin yksi erottava tekijä hyvän ja keskinkertaisen tietoalustan kyvykkyyksissä. Tekninen julkaisuväylä, käyttöoikeuksien määrittelyprosessi, tiedon ymmärrettävyys sen kattavan kuvauksen kautta, rakenteellinen yhdenmukaisuus, sekä tiedon löydettävyys data catalog-tyyppisesti ovat ominaisuuksia, joihin tulisi tietoalustaa kehitettäessä mielestäni panostaa.
Myös Data Mesh:issä datan saatavuuteen liittyvät ominaisuudet ovat nostettu osaksi sen esittämää arkkitehtuurimallia. Vastaavat ominaisuudet ovat toki toteutettavissa muissakin arkkitehtuureissa täysmääräisinä. Näiden ominaisuuksien varmistaminen ei ole siis niinkään arkkitehtuurillinen tai tekninen haaste, kuin tiedon hallinnallinen vaatimus ja priorisointi kysymys. Jos näiden tärkeiden kyvykkyyksien toteuttamista ei hallinnallisesti vaadita, jää ne hyvin usein täyttämättä.
Kehittäjien ja liiketoiminnan tulisi tehdä kehitystä yhdessä
Yksi pitkään datakehittämistä piinanneista haasteista on ollut liiketoiminnan sitominen tiiviiksi osaksi kehittämisprosessia. Liiketoiminnan kevyestä osallistumisesta syntyy ongelmia, kuten epätarkat tai paikoin jopa virheelliset määrittelyt, kehityksen toteutuminen vesiputousmallisesti palautteen puuttuessa, sekä huonosti liiketoimintaa mallintavien tai palvelevien toteutuksien tuottaminen vaadittavan liiketoiminnallisen ymmärryksen puuttuessa. Ehkäpä tiedon raportointi ja analytiikka on koettu pakollisena pahana, sen sijaan, että ne olisi nähty potentiaalisina työkaluina toiminnan optimointiin ja uusien työtapojen luomiseen. Onneksi kehittyneenanalytiikan hankkeet ovat pikkuhiljaa muuttamassa tämän tyyppisiä asenteita.
Data Mesh ehdottaakin, että kehittäjät keskittyisivät toteuttamaan tuotoksiaan ainoastaan tietyn tai tiettyjen liiketoiminta-alueiden kanssa, Data Mesh:in termein: domain:ien.
Ajatuksena on siis se, että myös kehittäjät ajansaatossa ymmärtäisivät syvemmin heille nimitettyjä liiketoiminnan osa-alueita.
Käytännössä tämä tapahtuisi siten, että datakehitystä tehdään liiketoiminnan hallinnoimana ja sen kanssa tiiviissä yhteistyössä. Liiketoiminnoilla olisi omat datatiimit, joiden osana tulisi aina olla liiketoiminnassa toimivia henkilöitä. Itse koen, että tämä malli on potentiaalisesti paljon toivottavampi, kuin IT-vetoinen datakehitys, jossa monesti esiintyy rikkinäisen puhelimen haasteita. Joskus olen ollut todistamassa jopa tapauksia, joissa raportin kehittäjä ei ole voinut keskustella suoraan sitä hyödyntävien käyttäjien kanssa. Tällaisessa tapauksessa ei voi kovinkaan useasti odottaa lopputuloksen olevan käyttäjälle optimaalinen.
Data tuotteena vaatii omistajuuden
Data Mesh hallintamallina perustuu domain:ien lisäksi Data as a Product käsitteeseen, suomalaisittain data tuotteisiin. Sen lisäksi, että se on Data Mesh:issä hallinnallinen yksikkö, on siinä se myös arkkitehtuurillinen yksikkö. Tällöin puhutaan Data Quantum:ista. Keskityn nyt nimenomaan Data product:iin hallinnallisena konseptina. Datasta tuotteena voisi helposti kirjoittaa oman kokonaisen sarjan artikkeleita. En siis lähde syvällisesti avaamaan sen kaikkia hienouksia, mutta siinä on kuitenkin muutamia tärkeitä ominaisuuksia verrattuna Data as an Asset-tyyppiseen ajatteluun, joita koitan tuoda esiin.
Tiedon omistajuus tuntuu monesti olevan haastava asia. Dehghani väittää, että perinteisissä arkkitehtuureissa tiedon omistaa IT. Tätä väittämää en itse allekirjoita lainkaan, mutta myönnän, että myös omasta kokemuksesta, tiedon omistajan kaivaminen on välillä erittäin haastavaa. Omistajan löytäminen tiedolle erityisen vaikeaa silloin kun tietoa ajatellaan hyödykkeenä. "Data is the new oil"-slogan pyöri ympäriinsä muutama vuosi sitten, ja tämä kuvastaa mielestäni ongelmaa hyvin. Hyödyke on kyllä arvokasta, mutta se on hallinnollisesti vain epämääräinen raaka-aine. Kun öljystä jalostetaan sitten vaikkapa voiteluaina, se laitetaan purkkiin ja brandataan, niin alkaa omistajakin löytyä. Ongelma datan kanssa on siinä, että se ei ole geneerinen klöntti raaka-ainetta edes sen lähteellä. Tieto kuvaa lähtökohtaisesti aina jonkin liiketoiminnan prosessia, tai on kerätty sellaista tukemaan.
Ajattelutavan muutos tiedosta tuotteena, jo sen alkulähteiltä asti, ajaa siihen, että tiedolle asetetaan omistajan lisäksi muitakin vaatimuksia varhaisessa vaiheessa. Oletamme tuotteelta aina tietyn tasoista laatua, toimitusvarmuutta ja saatavuutta. Laatutason ja toimitusvarmuuden varmistamiseksi täytyy jonkun yksittäisen tahon hallita sen koko elinkaarta. Data tuotteena vaatii siis omistajan. Kuljettava (toimittava) organisaatio, kuten IT ei voi olla vastuussa itse tuotteesta.
Lisäksi erona puhtaaseen raaka-aineeseen, tuotteelle hyväksytyt poikkeamat tulee määritellä. Ja mikäli huonolaatuinen tuote päätyy käyttöön, on ensiarvoisen tärkeää, että kuluttajat ovat tästä tietoisia. Datatuotteen laatu ei voi ollakaan siis "mitä tahansa lähteestä tulee", vaan myös lähdedatan laadun poikkeamia tulisi vähintäänkin seurata, hallinnoida, korjata ja raportoida. Data Mesh:issä puhutaankin tuotteelle asetettavasta sopimuksesta, joka on kaikkien nähtävissä ja josta sen tuottava, eli omistava, taho on vastuussa.
Jos data tuotteen lähde on puhtaasti tekninen tai ulkoinen, voi laadun poikkeamien poistaminen olla käytännössä hyvinkin haastavaa. Tällöin sopimus laadusta voi olla laatupoikkeamien raportointi, kuten virheellisten tietojen merkkaaminen tai poistaminen. Datatuotteille asetettavien sopimusten sisältö siis vaihtelee, niiden lähteen, prossien ja kypsyystason mukaisesti.
Tärkeää on kuitenkin se, että kaikille tahoille on selvää millaisia poikkeamia tiedoissa voi olla ja vastaavasti millaiset poikkeamat tulee nähdä ja käsitellä virheinä.
Mitä pidemmälle tuote on jalostettu, sitä vähemmän siinä sallitaan poikkeamia.
Tämä ajatus konkretisoituukin erittäin hyvin esimerkiksi data lakehouse:lle tyypillisessä mitaliarkkitehtuurissa (bronze, silver, gold). Kyse ei ole siis pelkästään Data Mesh:ille ominaisesta käsitteestä.
Onnistumista tulisi mitata tyytyväisyyden kautta
En ole kovinkaan usein törmännyt siihen, että data-alusta hankkeiden onnistumista konkreettisesti mitattaisiin. Siitäkään huolimatta, että onnistumisen mittaaminen on yksi Leanin ja ketterien kehitysmenetelmien kulmakiviä. Dehghani ehdottaakin, että mittaisimme Data Mesh:in onnistumista käyttäjien tyytyväisyyden kautta, sen sijaan, että sitä mittaisiin esimerkiksi rakennettujen data product:ien määrällä, tai muulla vastaavalla teknisellä mittarilla. Tämä korreloi mielestäni vahvasti arvon mittaamisen kanssa, koska data, jota kukaan ei halua tai pysty käyttämään ei mitenkään voi olla arvon tuotollisesti optimoitu.
Tyytyväisyyden mittaamiseksi, Deghani esittelee yhtenä vaihtoehtona, kollaboraatio tyyppisesti palautteen keräämisen. Vastaavaa toiminnallisuutta on visioitu ennenkin ainakin raporttien yhteydessä.
Kyseessä voisi olla esimerkiksi ihan tavallinen arviointi yhdestä viiteen, jota käyttäjät voisivat antaa.
Samalla voitaisiin kerätä myös tarkempaa palautetta kehitystarpeista, sekä tiedossa havaituista ongelmista. Havaittujen virheiden linkittäminen suoraan siihen liittyvään tietoon, on myös yksi kehittyneen tiedonlaatukonseptin ominaisuuksista.
Yhtenä onnistumisen mittarivaihtoehtona voidaan nähdä myös käytön laajuus. Eli kuinka monessa raportissa, rajapinnassa tai muussa jakelupisteessä kutakin datatuotetta käytetään. Data Mesh:in arkkitehtuurikonseptin yksi eduista onkin se, että datatuotteiden käytön seuranta tulee siinä vakiona, koska tuotteen käyttöön tulee rekisteröityä. Keskitetymmissä arkkitehtuurimalleissa vastaava mittaus ei välttämättä ole itsestäänselvyytenä tarjolla, ainakaan ilman data katalogia. Riittävän laajasti toteutetun data lineage:n kautta käytön laajuutta kuvaavan mittarin luominen tulisi olla kuitenkin täysin mahdollista, jopa yksinkertaista. Tämäkään idea ei ole siis niinkään kiinnitetty pelkästään Data Mesh:iin, vaan ennemminkin kyseessä on hyvin toteutetun tietoalustan ominaisuus.
Data Mesh:istä ajattelemisen aihetta
Gartner arvioi Data Mesh:in hyödyllisyyden alhaiseksi (Gartner Hype Cycle for Data Management 2022) ja luettuani Dehghanin kirjan (Data Mesh - Delivering Data-Driven Value as Scale) myönnän, että jotkin kohdat ja perustelut herättävät epäilyksiä. Dehghani kuitenkin itse kirjassaan myöntää, että Data Mesh on vielä sen hyvin varhaisessa kehitysvaiheessa. Mielestäni ei olisi ollut oikein arvostella kesken olevaa mallia. Joten sen sijaan, että olisin arvioinut Data Mesh:in hyötyjä ja haittoja, sen nykyisellä maturiteetilla, halusin nostaa esiin asioita ja ideoita, jotka itse koin siinä hyödyllisiksi tai lupaaviksi. Ennen kaikkea esitellyt aiheet ovat mielestäni käyttökelpoisia valitusta hallinta mallista tai arkkitehtuurista huolimatta.
Suosittelen Dehghanin kirjan lukemista, mikäli Data Mesh oikeasti syvemmin kiinnostaa. Kirjassa nostetaan esiin paljon sellaisia kulmia, mitä aiheeseen liittyvissä blogeissa vähemmän on käsitelty. Ehkä tärkeimpänä huomiona se, että kyseessä on kokonaisvaltainen ajattelumalli sisältäen vaatimuksia, aina organisaation rakenteesta, julkaistavan data toteutuksen toiminnallisuuksiin asti. Toisin sanoen, Data Mesh:in vaatimukset ja käytännöt ylettyvät paljon pelkkää data-alustaa ja sen hallintaa laajemmalle.
Huolimatta siitä, mikä Data Mesh:in kohtalo lopulta tulee olemaan, tarjoaa se useita ajattelemisen arvoisia konsepteja, joita on toimintatapa ja hallintamallimielessä sovellettavissa helposti laajemminkin.
Yksinään monikaan näistä konsepteista ei välttämättä ole kovinkaan uusi ja mullistava, mutta ovat ne silti sellaisia, joiden puute aiheuttaa monesti haasteita data kehityksessä. Vaikka Data Mesh:in toteuttaminen teknisesti ei tarjoaisi riittävästi arvoa, soveltuisi hyvin organisaation tarpeisiin tai toimintatapoihin, voi sen sisällöstä silti ottaa oppia ja ammentaa parhaiten itselle soveltuvia kehitystä tehostavia malleja.