Organisatorisen datan ja raportoinnin salaisuudet
Mistä tämä data oikein tulee?
Mitä sille tapahtuu; onko tämä mitä itse näen saman muotoista ja nimistä kuin itse datan lähteessä?
Näenkö kaiken?
Näkevätkö muutkin saman kuin minä, samoilla nimillä ja arvostuksella ilman että mitään on filteröity tai rajattu pois?
Kuka kumma tämän datan oikein omistaa ja siitä vastaa?
Missä kaikkialla tätä dataa oikein käytetään ja millä tavalla?
Kohdistuuko dataan minkäänlaisia muutoksia tai prosessointeja ennen kuin se saavuttaa tämän raportin?
Jos haluan rikastaa raporttia lisää, ovatko tarvitsemani datat ja lähteet jo hallussamme?
Lukuisia kysymyksiä jotka kaikki ovat saman ongelman ilmentymiä: usein on todella hankalaa hahmottaa kokonaisuutta ja edes saada tietoon kaikkia palapelin osasia, jotka lopulta muodostavat konkreettisen lopputuloksen esimerkiksi raportin muodossa. Kuinka tähän kaikkeen voi oikein saada selvyyttä ja vastauksia?
Data Catalogit
Yrityksen omistaman datan ominaisuuksien kartoitukseen sekä kaiken siihen liittyvän oheistiedon ja metadatan keräämiseen on aikojen kuluessa kehitetty työkaluja, data catalogeja, joita löytyy markkinoilta lukuisia. Yksinkertaisimmillaan on myös käytetty kaikille tuttuja työkaluja kuten Exceliä tämän tiedon koostamiseen ja hallinnoimiseen. Riippumatta lähestymistavasta, ratkaisut eivät ole olleet kokonaisuuden kannalta erityisen helppokäyttöisiä tai kattavia; scope on ollut rajoittunut sekä käytettävyys hankalaa ja siiloutunutta.
Azure Data Catalog Gen1 oli Microsoftin aikaisempi ratkaisu datan näkyvyyden lisäämiseen organisitorisesta perspektiivistä, mutta sisälsi omat rajoituksensa käytettävyyden suhteen. Joulukuun 2020 alussa Public Preview -vaiheeseen julkaistu Gen2, uudelta nimeltään Purview, on iso loikka eteenpäin käytettävyyden, hallittavuuden, visuaalisuuden ja laajennettavuuden saroilla.
Purview
Purview automatisoi ison osan prosessista skannaamalla määritellyt lähteet ja luokittelemalla nämä automaattisesti niin sisäänrakennettujen (mukaanluettuna GDPR:n alaiset asiat kuten yksilön tunnistamiseen liittyvä data kuten nimi, osoite, sähköposti, luottokortin numero, jne.) kuin myös organisaation määrittelemien custom-luokittelujen mukaisesti. Lopputulemana tarjoillaan graafinen esitys kokonaisuuden hahmottamiseksi. Karkealla tasolla prosessi on niinkin yksinkertainen kuin:
- Määrittele tietolähteet
- Määrittele skannauksen parametrit
- Aja skannaukset
Luokittelun lopputulos on nähtävissä graafisessa muodossa alla olevan esimerkin mukaisesti:
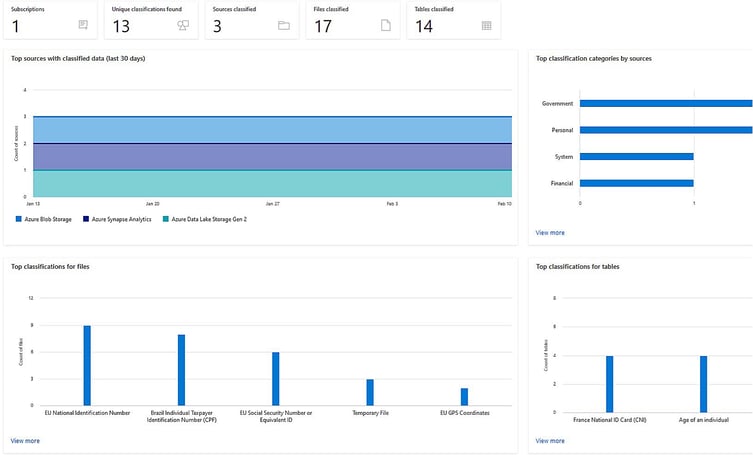
Huomionarvoista on, että algoritmeihin perustuva luokittelu voi aina tuottaa vääriä positiivisia osumia, mutta jopa yksittäinen skannaus antaa kullanarvoista tietoa minkä muotoista dataa organisaatiolla on ja mitkä osat ovat potentiaalisesti sensitiivisiä ja ehkä vaativat erikoistoimenpiteitä anonymisoinnin sekä pääsyn hallinnan suhteen kaikilla tasoilla datan koko elinkaaren aikana.
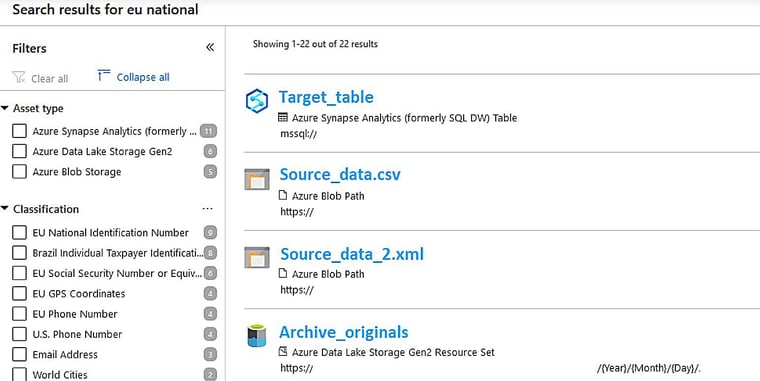
Luokittelut ovat osa Purviewin hakutoiminnallisuutta, joten tietyn luokittelun mukaiset datasetit on helppo löytää. Esimerkiksi haettaessa ylläolevan esimerkin luokittelemalla termillä ‘EU national’, palautuu listaus kaikista dataseteistä, jotka on tällä tavalla luokiteltu.
Lähteet ja niiden hallinta
Purview tulee tukemaan isoa joukkoa lähteitä valmiiksi sisäänrakennettuna tarjoamalla suorat connectorit useisiin ei-Microsoft-pohjaisiin tuotteisiin, kuten SAP, AWS S3 ja Teradata. Kirjoitushetkellä Suomeen saatavilla olevissa Azure data centereissä on tuettuina vain Azure-ratkaisuja kuten SQL Server, Synapse ja Data Lake Storage. Tämä lista kuitenkin kasvaa, ja on todennäköisesti huomattavan paljon kattavampi, kun Public Preview -vaihe helmikuun lopussa päättyy.
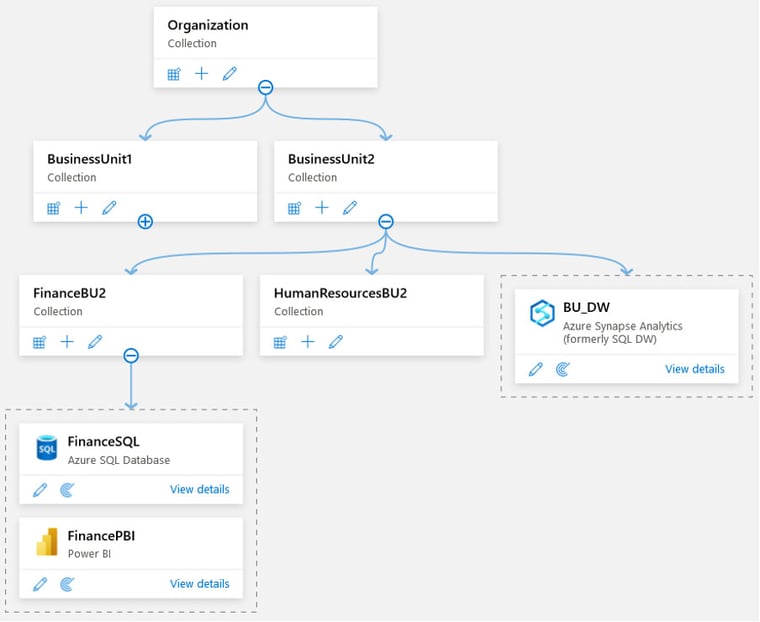
Organisatorisen datapääoman hallittavuuden osalta lähteitä voidaan luokitella omiin “kokoelmiinsa” oheisen kuvan mukaisesti. Päätason alle voidaan luoda alisteisia “kokoelmia”, jotka voivat sisältää lisää kokoelmia jne. Jokaisen tason “kokoelma” voi sisältää lähteiden yhteysmäärittelyitä, joita voidaan siten skannata. Kokoelmat ovat erinomainen keino luokitella järjestelmiä, jotka eivät välttämättä noudata yhteistä nimeämiskäytäntöä tai ovat tulleet osaksi organisatorista tietopääomaa esimerkiksi yrityskaupan seurauksena.
Data lineage
Yksi tärkeimmistä ominaisuuksista jonka Purview tuo työkalupakkiin, on data lineage visualisoituna ja automatisoituna. Kirjoitushetkellä Purview osaa luoda täydellisen end-to-end lineagen lähteestä kohteeseen ja hyödyntäjään tiettyjen olosuhteiden vallitessa. Nämä olosuhteet ovat:
- Skannauksen lähde on joku Azuren omista palveluista (blob, sql, dw)
- Orkestrointi tapahtuu Data Factoryllä ja käytössä on vain joku/jotkut seuraavista activityistä:
- Pipeline
- Data flow
- SSIS package (custom-paketit eivät ole vielä tuettuja)
- Hyödyntäjä on Power BI-raportti
Purview rakentuu Apache Atlaksen perustalle, ja mahdollistaa kaikkien tämän tarjoamien REST APIen hyödyntämisen niin kyselyiden kuin datan rikastamisen osalta. Tämä puolestaan mahdollistaa sen, että esimerkiksi data lineagea voidaan laajentaa ja rikastaa RESTien kautta esimerkiksi prosesseilla joita Purview ei tue vielä automaattisesti. Tällaisia prosesseja voivat olla esimerkiksi Data Factoryn kutsumat SQL stored proceduret, ML-mallinnukset ja Databricks-prosessit.
Ohessa esimerkki rikastetusta lineagesta: prosessi ’custom process via REST API’ on lisätty Purview’n catalogiin ja liitetty kahteen datasettiin: lähteeseen ja kohteeseen.

Sama lineage lähteen vinkkelistä, jossa seurataan lähteen atribuuttien muutoksia eri vaiheissa. Tämä havainnollistaa muutokset attribuuttien nimeämisissä ja dataan potentiaalisesti tehtyjen muutosten dokumentoinnin attribuutin tasolla. Allaolevan esimerkin mukaisesti custom objektien avulla toisiinsa liitettyjen datasettien attribuuttitason lineage ei kuitenkaan ole automaattista, vaan vaatii tarkempaa metadatan hallintaa.

Hallittavuus ja roolit
Data Catalog Gen1 oli rajoitettu vain yhteen per Azure Tenant, eli käyttötapaukset ja ryhmitykset tuli miettiä hyvin tarkasti. Purview-instanssien määrää taasen ei ole rajoitettu, joka mahdollistaa useiden luonnin ja hallinnan samassa Tenantissa ja jopa saman Subscriptionin sisällä. Yksi potentiaalinen käyttöskenaario on esimerkiksi business unit -kohtaiset instanssit, jotka on pyhitetty yksikkökohtaisiin järjestelmien hallintaan, sekä globaalimman scopen ‘data platform’ catalogit tarkkaan hallitulla käyttäjämallilla. Eri Purview-instanssien linkittäminen keskenään on yksi potentiaalinen lisä joka tarjoaisi välitöntä lisäarvoa, mutta tämän osalta tietoa onko tätä ominaisuutta odotettavissa tulevaisuudessa, ei ole kirjoitushetkellä.
Purview tarjoaa kolme custom-roolia eri käyttäjiä varten. ‘Purview Data Reader Role’ on puhtaasti consumer-rooli ja antaa ainoastaan oikeudet lukea dataa. ‘Purview Data Curator Role’ on tarkoitettu sovelluksen hallintaan sekä assetien kommentointiin, luokittelujen ja business glossaryn päivittämiseen jne. ‘Purview Data Source Administrator Role’ ei sisällä mitään ylläolevien oikeuksista, ja on tarkoitettu vain skannien määrittelyyn ja potentiaaliseen operointiin. Näiden kolmen yhdistelmillä saadaan käyttäjille tarvittavat oikeudet.
Purviewin malli mahdollistaa ja pehmeällä tavalla “pakottaa” pistämään organisatoriset vastuut datan suhteen kuntoon, joten tilaisuus kannattaa hyödyntää ja paneutua datan & prosessien omistajuuksiin ja rooleihin eri data domainien, business unitien jne. suhteen. Kunnolla suunniteltu pohja antaa eväät tuotteen menestyksekkäälle hyödyntämiselle pitkälle tulevaisuuteen.
Purview-käyttöönotto kuuluu osaksi Architecture Governance / Data Management -kokonaisuuksia.
Linkitykset: