Marko Oja
Data-arkkitehti, joka auttaa asiakasta ymmärtämään tekniikan mahdollisuudet ja muuntaa innovatiiviset ideat teknisiksi ratkaisuiksi. Ketterät kehitysmenetelmät ja kehitystyötä tukevat prosessit ovat lähellä Markon sydäntä.
Keskustelu Azure Purviewin ympärillä käy kuumana ja aihe on monilla mielessä. Sen mahdollisuudet ja toiminnallisuudet vakioprosessien ulkopuolelta jäävät kuitenkin usein vähemmälle huomiolle. Blogissa esitellään käyttötapauksia, jotka vaativat Purviewin toiminnallisuuksien laajentamista, sekä millaisia vaihtoehtoja näiden toteuttamiseksi on olemassa.
Blogikynää alkoi taas pienen tauon jälkeen syyhyämään, kun tuli vastaan aihe, josta en löytänyt kunnollista kirjoitusta edes englanniksi. Päätinkin vetää nyt yhden kotiinpäin ja avata asiaa ensin suomeksi.
Aiheena on siis Purviewin tietojen massapäivitysten tekeminen: Esimerkiksi uusien tietojoukkojen lisäämisestä tai suuren määrän skannauksen pohjalta syntyneiden tietojen poistamisesta. Moni saattaakin olla jo tutustunut Purviewin tarjoamaan Atlas API-rajapintaan. Mikäli nämä eivät vielä ole entuudestaan tuttuja, kyseessä on siis Purviewin ohjelmalliset rajapinnat. Nöiden rajapintojen kautta voidaan tehdä melkein kaikki sama tiedon päivitysoperaatio, kuin käyttöliittymästäkin - joskus jopa enemmänkin tai ainakin astetta helpommin. Näiden rajapintojen käytössä tulee kuitenkin joskus vastaan tiettyjä käytännön rajoitteita, varsinkin silloin kun käsiteltäviä operaatioita on todella paljon. Vaihtoehtona onkin tehdä vastaavia operaatioita Purviewin Event Hub päätepisteen (endpointin) kautta. Tämä tapahtumajonopohjainen käsittely skaalaa huomattavasti rajapintoja paremmin suurempiinkin määriin operaatioita. Mutta ennen kuin sukelletaan syvään päähän, niin kerrataanpa hieman mistä tässä oikeastaan on kyse.
Aloitetaan toteamalla että, Purview on Microsoftin kohtuullisen uusi Azuren päällä pyörivä datakatalogi (https://azure.microsoft.com/en-us/products/purview/). Purview myös "korvaa" edellisen Azure Data Catalog-nimellä kulkeneen palvelun. Käytännössä se on tämän edellisen palvelun seuraava kehitysversio. Purviewin käyttö hyvin korkealla tasolla ja pähkinän kuoressa menee seuraavasti:
Päämääränä on siis rekisteröidä ja luokitella kaikki lähteet ja niiden tiedot, jotta ne olisivat helposti löydettävissä. Tähän liittyy liiketoimintatermien linkittäminen tietoihin, kuten esimerkiksi mistä kaikkialta asiakastiedot ovat löydettävissä:
Merkitsemällä tietojoukoille termistöt, luokittelut ja prosessivuot pyritään mahdollistamaan, että tietoa tarvitsevien ja hyödyntävien toimijoiden olisi mahdollisimman helppo löytää ja ymmärtää tarjolla olevaa sisältöä.
Tähän kokonaisuuteen liittyy toki paljon asioita, joita täytyy lisäksi hallinnoida ja määritellä, mutta tämän artikkelin pohjaksi tämä käytön määritelmä riittänee antamaan riittävän kontekstin.
Koska Purviewin kehitys menee valtavaa vauhtia eteenpäin, uusia ominaisuuksia ja skannausta tukevia lähteitä lisätään kunnioitettavaa tahtia. On kuitenkin tiettyjä käyttötapauksia, jotka ovat joko vielä tukemattomiin lähteisiin liittyviä, reaalimaailman mahdollisuuksien ulottumattomissa tai esimerkiksi kustannusteknisesti järjettömiä ratkaistavaksi perustoiminnallisuuksilla. Tällaisia voivat olla esimerkiksi:
Mainittakoon, että esimerkiksi tiedon luokitteluun Purview tarjoaa jo automatiikkaa. Ja Microsoftin panostuksen huomioiden (ilman suurempia juonipaljastuksia tekemättä), automatisoinnin tason voidaan olettaa kasvavan tulevaisuudessa entisestään.
Jos vastaan on tullut siis sellainen tilanne, jossa perustoiminnallisuuksilla ei tavoitettu haluttua lopputulosta, niin miten voitaisiin katalogin tietoja kuitenkin täydentää?
Ensimmäinen vaihtoehto on tehdä päivitys manuaalisesti käyttöliittymän kautta. Mikäli tarvittavaa metadataa ei ole muualla tarjolla, saattaa tämä olla ainut vaihtoehto. Sen voi nähdä myös osana datan latausputkien dokumentointia.
Sen sijaan, että prosessointi kuvataan erilliseen dokumenttiin, voidaan se mallintaa osaksi datakatalogia. Dokumentaatiot jäävät monesti hyödyntämättä, koska niiden löytäminen on haastavaa. Osana data katalogia dokumentaation potentiaalinen arvo kasvaa huomattavasti.
Mikäli tarvittava tieto kuitenkin löytyy jo jostain, kuten latausprosessin metamäärittelystä tai koodin konfiguraatioista, ei ole hirveästi mieltä ylläpitää vastaavaa tietoa käsin toistamiseen. Todellisuudessa kun lähes kaikki dokumentaatio, jota joudutaan päivittämään kahteen paikkaan, jää nopeasti jälkeen ja vanhenee.
Toisena, enemmän automaatioon pohjautuvana vaihtoehtona, on muokata datakatalogin tietoja sen tarjoamien rajapintojen kautta. Purviewin rajapinnat ovat itse asiassa hyvin kattavat ja suhteellisen helppokäyttöiset. Rajapintojen käyttöön liittyy kuitenkin skaalaushaaste: Tuhansien (tai pahimmassa tapauksessa miljoonien) operaatioiden ajaminen rajapintojen kautta voi yksinkertaisesti olla liian hidasta. Rajapinnoista aiheutuu väkisinkin latenssia yhteyden avaamisen ja operaatioiden suorittamisen osalta. Jos operaatioita ei ole teknisesti tai prosessillisesti mahdollista toteuttaa massaoperaatioina, tai suoritettavien operaatioiden määrä kasvaa liian suureksi, saattaa rajapintojen käyttö muodostua ongelmalliseksi. Rajoittavaksi tekijäksi voi muodostua myös kustannusten kasvu, kun Purview kasvattaa instanssin kokoa skaalautumaan rajapintakutsujen käsittelyä varten.
Kolmanneksi vaihtoehdoksi muodostuukin Purviewin Kafka (Event Hub) tapahtumaoperaatioiden hyödyntäminen. Tapahtumajonoa voidaan käyttää sen sijaan, että esimerkiksi data-assetit lisättäisiin rajapintakutsun kautta. Tämän tavan hyvänä puolena on se, että päivitykset tapahtuvat lähes reaaliaikaisella nopeudella. Huonona puolena on se, että viestin käsittelyn lopputuloksesta, ei rajapintapyynnön tapaan saada suoraan vastausta. Kyseessä on siis asynkroninen viestintämuoto, jossa toiseen jonoon laitetaan käsiteltävät pyynnöt, ja toisesta jonosta luetaan prosessoitujen pyyntöjen lopputulos. Mikäli haluaa olla varma, että kaikki operaatiot on suoritettu onnistuneesti, täytyy rakentaa käsittely lähetettyjen ja suoritettujen operaatioiden yhdistämiseksi. Tällainen prosessi on onneksi yksinkertaista operaatioiden listaamista ja niiden lopputuloksien päivittämistä, sekä mahdollisien ongelmatilanteiden uudelleenkäsittelyä. Kuvatunlainen käsittely lisää kuitenkin sen verran toteutuksen monimutkaisuutta, ettei sitä kannata täysin syyttä hyödyntää. Silloin kun käyttötapaus kuitenkin vaatii tavallista suurempaa skaalausta, on operaatioiden käsittely tapahtumajonon kautta kullanarvoinen ominaisuus.
Todettakoon siis, että Purview tarjoaa kattavat ominaisuudet, joilla täydentää sen omia toiminnallisuuksia, sekä rajapintojen, että tapahtumajonon muodossa. Tällaiset kyvykkyydet ovat erittäin tärkeitä silloin kun mietitään, voidaanko jotakin tuotetta ottaa koko organisaationlaajuiseen käyttöön.
Ei varmastikaan haluta päätyä tilanteeseen, jossa valittu palvelu ei yksinkertaisesti jousta uusiin tarpeisiin, edes kustomoinnin kautta. Toki optimitilanteessa tuotetta käytetään aina mahdollisimman pitkälle sen valmiisiin ominaisuuksiin tukeutuen. Kuitenkin datamaailman nopeassa murroksessa olisi naiivia ajatella että rajatapauksia, niinkin laajaa kokonaisuutta kuin kaikkea organisaation hallussa olevaa tietoa luetteloitaessa, ei tulisi koskaan syntymään.
Cloud1 on toteuttanut erilaisia skenaarioita Purviewin ja aiemmin myös Azure Data Catalogin parissa. Mikäli kaipaat tukea Purviewin käytössä, tai mietit sen käyttöönottamista, niin kerromme mielellämme lisää kokemuksistamme ja referenssitarinoistamme.
Ennen kuin päästään itse asiaan täytyy Purviewin Event Hub (Kafka Endpoint) aktivoida. Onneksi se on vain yhden valinnan takana.
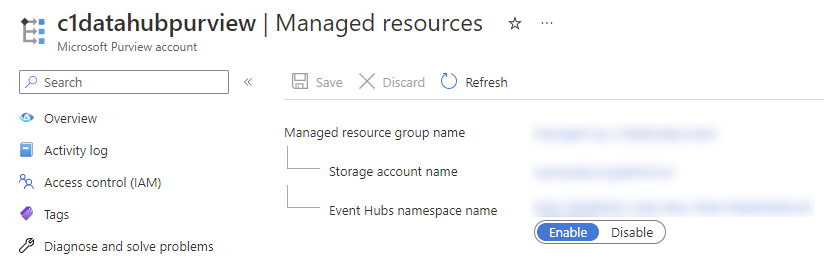
Kun aktivointi on suoritettu, löytyy Azure portaalista Purviewin properties-valikon takaa Atlas Kafka endpoint primary connection string-arvo. Tätä yhteysmerkkijonoa käytetään, kuten Event Hubiin normaalistikin yhdistyttäessä. Operaatioiden suorittamiseksi Event Hub:in nimeksi asetetaan ATLAS_HOOK. Kuunneltaessa operaatioiden tuloksia nimeksi valitaan taas ATLAS_ENTITIES.
Even Hubin kutsumiseksi voi käytännössä käyttää mitä tahansa haluamaansa tapaa. Tässä esimerkiksi yksinkertainen Python esimerkkitoteutus.

Lisää ohjeita löytyy esimerkiksi täältä https://learn.microsoft.com/en-us/azure/purview/manage-kafka-dotnet
Tämän jälkeen täytyykin ainoastaan tietää millainen viesti Purview tapahtumaan tulee lisätä.
Uuden data-assetin luominen onnistuu esimerkiksi näin:
{ "message": { "entities": { "entities": [ { "typeName": "azure_datalake_gen2_path", "attributes": { "owner": "$superuser", "qualifiedName": "https://mgestoaccdldev.dfs.core.windows.net/source-files/node-1545806377854232961/", "path": "/source-files/node-1545806377854232961/", "isFile": false, "size": 0, "name": "node-1545806377854232961" }, "collectionId": "aos26b" } ] }, "type": "ENTITY_CREATE_V2", "user": "admin" }, "version": { "version": "1.0.0" }}
Vastaavasti luodun data-assetin size attribuutin päivittäminen onnistuu taas näin:
{
"message": {
"entityId": {
"typeName": "azure_datalake_gen2_path",
"uniqueAttributes": {
"qualifiedName": "https://mgestoaccdldev.dfs.core.windows.net/source-files/node-1545806377854232961/"
}
},
"entity": {
"entity": {
"typeName": "azure_datalake_gen2_path",
"attributes": {
"size": 9876
}
}
},
"type": "ENTITY_PARTIAL_UPDATE_V2",
"user": "admin"
},
"version": {
"version": "1.0.0"
}
}
Ja lopuksi kyseisen assetin poistaminen tällä tavalla:
{ "message": { "entities": [ { "typeName": "azure_datalake_gen2_path", "uniqueAttributes": { "qualifiedName": "https://mgestoaccdldev.dfs.core.windows.net/source-files/node-1545806377854232961/" } } ],
"type": "ENTITY_DELETE_V2", "user": "admin" }, "version": { "version": "1.0.0" }}
Lisää tietoa ja esimerkkejä löytyy vielä täältä: https://github.com/devlace/purview-pubsub
Lähetettävien viestien muodossa on tiettyä hajontaa, joten niiden muodostamisessa kannattaa olla tarkkana. Kun prosessin saa kuitenkin kertaalleen toimimaan, on sitä tämän jälkeen erittäin helppo hyödyntää.