Marko Oja
Data-arkkitehti, joka auttaa asiakasta ymmärtämään tekniikan mahdollisuudet ja muuntaa innovatiiviset ideat teknisiksi ratkaisuiksi. Ketterät kehitysmenetelmät ja kehitystyötä tukevat prosessit ovat lähellä Markon sydäntä.
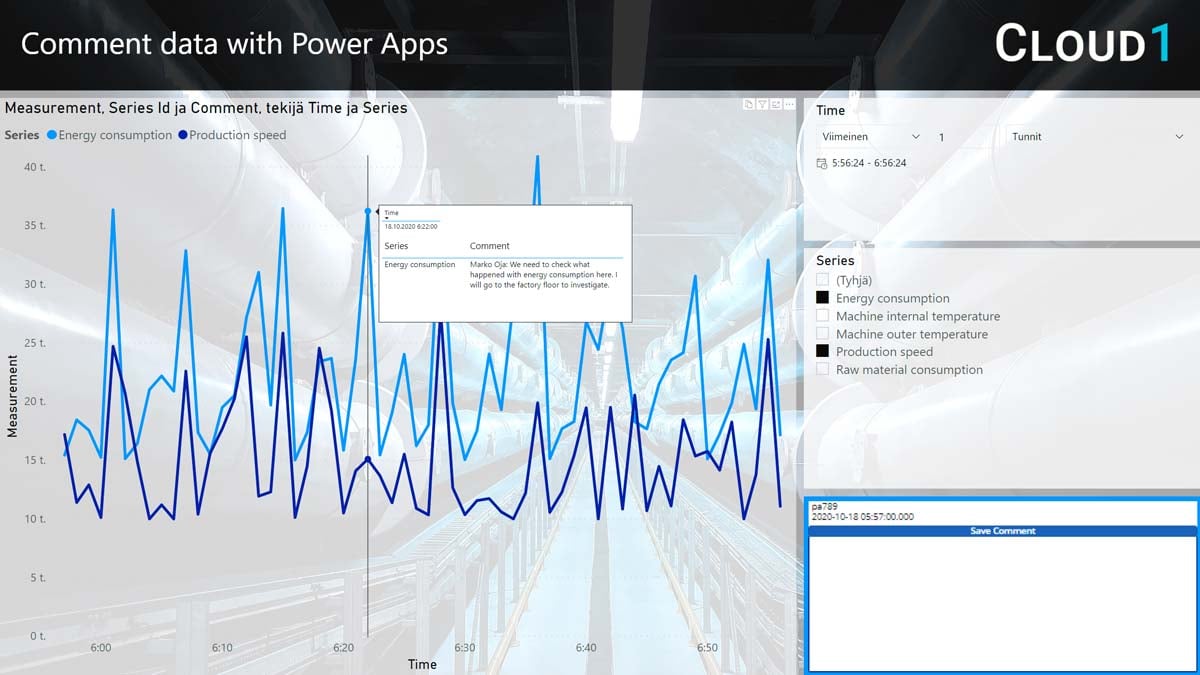
Tuotannon tehostamiseen johtavassa analyysissä käyttäjä havaitsee poikkeaman erään mittalaitteen tiedoissa. Käyttäjä valitsee poikkeaman graafilta, kirjoittaa viestin ja lähettää havainnon eteenpäin raportilta. Tieto merkitään epäluotettavaksi, ja sitä hyödyntävät raportit indikoivat tilanteen käyttäjille. Heräte mahdollisesti epäluotettavasti tiedosta lähetetään tiedosta vastaavalle henkilölle, mukanaan informaatio siitä, kuka merkinnän on tehnyt ja miksi se on merkattu. Mukana kulkee myös tarkka tieto siitä millä sarjalla ja aikaleimalla poikkeama on havaittu. Lisäksi tehtaan ylläpitotiimille saapuu pyyntö tarkistaa mittalaitteen toiminta. Nämä toimenpiteet tapahtuvat muutamassa sekunnissa havainnosta, ilman sähköposteja tai puhelinsoittoja.
Tämän skenaarion ei pitäisi kuulostaa mahdottomalta tai edes kovin vaikealta.
Uskallan väittää, että virheiden ja poikkeavuuksien havaitsemisesta on tullut aikaisempaa helpompaa ja vaivattomampaa. Ainakin, kun tilannetta verrataan aikaan, jolloin pääosa tiedosta oli vielä näkyvillä ainoastaan staattisilla taulukkoraporteilla. Avuksi olemme saaneet helpommat työkalut analysoida ja visualisoida tietoja. Tämän lisäksi edistyneemmät järjestelmät käyttävät tarkistussääntöjä, algoritmeja ja tekoälyä tietojen tarkistamiseksi. Olemme kehittyneet paremmiksi tiedon laadun validoinnissa. Hyvä me!
Virheiden validointi- ja korjausprosesseissa ei kuitenkaan välttämättä ole tiedon analysointia vastaavaa vaivattomuutta. Ensimmäisenä haasteena on se, että tiedon korjaamisen prosessia ei ole määritelty tai kuvattu. Käyttäjä havaitsee poikkeaman entistä helpommin, mutta tästä seuraaville toimenpiteille ei ole selkeätä toimintaohjetta.
Vaikka käyttäjä tietäisi keneen virhetilanteessa voi olla yhteydessä, on kyseessä silti usein manuaalinen toimenpide, kuten puhelinsoitto tai sähköpostin lähettäminen.
Manuaaliseen vaihtoehtoon verrattuna tiedon laadun prosessien automatisoinnin etuina ovat:
Manuaalisia prosesseja on pyritty korvaamaan virheiden hallintaan vastaavilla erillisillä työvälineillä. Ongelmana niissä on se, että ne eivät ole osa analytiikka-alustaa. Tällöin virheellisen tiedon etsimiseen tarvittavat parametrit täytyy manuaalisesti siirtää raportilta, ja vastaavasti järjestelmän tiedot tulee ladata takaisin tietoalustaan. Prosessi on virheherkkä ja työläs, jolloin tarkka linkkaus alkuperäiseen tietoon usein menetetään. Jälkikäteen virheellisen datapisteen etsimisestä tulee ongelmallista. Jos poikkeamien raportointiin tarkoitettu työväline ei ole riittävän helppo, on käyttäjän helpompi sivuuttaa se ja käydä läpi manuaalinen prosessi.
Kokonaisuudessaan automatisoidut prosessit mahdollistavat sen, että prosesseja ja siihen liittyvää tietoa on helppo seurata, mitata ja kehittää.
Parhaimmillaan havainnon validointi- ja korjausprosessi tapahtuu nykyistä huomattavasti paljon automaattisemmin. Virheellinen tieto tulisi olla mahdollista korvamerkitä suoraan raportilta. Merkitsemisen tulisi käynnistää automaattinen, metadataan pohjautuva eli konfiguroitava prosessi havainnon validoimiseksi. Validoijan tulisi olla mahdollista palata haluttuun datapisteeseen, ja merkitä tieto virheelliseksi muita prosesseja, laskentoja ja analyysejä varten. Mahdollinen korjauspyyntö lähteelle lähtisi tämän toiminnon seurauksena. Toivotussa skenaariossa kaikki tämä olisi lähtöisin siis havainnosta ja toimenpiteestä suoraan raportilla.
Syyt olla rakentamatta analytiikkaohjattuja prosesseja ovat pitkään olleet osittain teknisiä. Raportointityövälineet eivät ole mahdollistaneet toimivia keinoja tiedon välittämiseksi prosesseihin. Vaihtoehtona on ollut rakentaa kustomoituja ratkaisuja, niin sanotusti pitkästä puusta koodaten, joissa raportointia on jollakin tekniikoilla sulautettu osaksi ohjelmistoja. Ongelmana tällaisissa ratkaisuissa on se, että niissä ei voida hyödyntää analytiikkatyövälineiden vakioituja käyttöliittymiä. Nopeasti kehittyvälle analytiikka-alustalle kustomoidun ratkaisun hyödyt ovat tavallisesti arvioitu huomattavasti haittoja pienemmiksi.
Microsoftin Power Platformin työkalut oikein hyödynnettyinä mahdollistavat uudenlaisen arkkitehtuurin toteuttamisen. Sen sijaan, että analyyseja sisällytettäisiin kustomoituihin applikaatioihin, voidaan low code -applikaatioita upottaa suoraan raportteihin. Objektina applikaatio käyttäytyy kuten mikä muu Power BI -objekti tahansa. Toisin sanoen, applikaatiota voidaan ohjata graafeissa ja filttereissä tehtyjen valintojen avulla. Tämä mahdollistaa yksityiskohtaisen tiedon keräämisen käyttäjän tekemistä valinnoista, joiden avulla prosesseja voidaan ohjata juuri halutulla tavalla. Applikaation upottaminen analysointityökaluun säästää useimmissa yksinkertaisissa käyttötapauksissa huomattavia määriä kehitystyötä, koska siinä voidaan hyödyntää Power BI -portaalin kaikkia olemassa olevia ominaisuuksia.
Sen lisäksi, että applikaatio saadaan osaksi raporttia Power Appsiä hyödyntäen, voidaan sillä ohjata muitakin Power Platformin prosesseja. Yhdistämällä applikaatio Power Automateen, voidaan tieto tallentaa tai lähettää käytännössä lähes minne tahansa. Tuettuna ovat niin erilaiset tietokannat kuin rajapinnatkin, Power Platformin Common Data Modelia unohtamatta. Helppokäyttöinen prosessin ohjaustyöväline mahdollistaa näin analytiikkalähtöisen ja metadataohjatun prosessin luomisen. Kaikki tämä ilman varsinaista koodaustarvetta, työkaluilla, joilla myös edistyneet businesskäyttäjät voivat ylläpitää toteutusta.
Laadukas tieto on arvokas omaisuus mille tahansa organisaatiolle. Toisaalta taas huono data voi olla pahimmillaan jopa vaarallista. Epätarkkaan tai virheelliseen tietoon pohjautuvat päätökset voivat olla kohtalokkaita. Tämä pitäisi mielestäni riittää yksinään syyksi lähteä rohkeasti kehittämään ja haastamaan nykyisiä tiedonhallintaan tarkoitettuja prosesseja.
Elämme lisäksi keskellä suurta murrosta tiedon lähteisiin liittyen. Uudentyyppiset tietolähteet, kuten striimit ja sosiaalinen media, alkavat olla jokapäiväisiä lähteitä tietoalustoilla. Nämä lähteet tuovat mukanaan korkeammat reaaliaikavaateet ja hyödynnettävien tietomassojen eksponentiaalisen kasvun, niin volyymissa kuin laajuudessakin. Vanhat laatuprosessit eivät ole riittävän nopeita vastaamaan kehityksen tuomiin haasteisiin.
Lähtökohtana toimivalle prosessille on selkeä strategia. Tiedon laadun parantamiseen tähtäävän strategian pohjaksi täytyy kartoittaa kuka tiedon omistaa, mihin sitä käytetään ja miten siinä löytyviin virheisiin reagoidaan. Toisin kuin vaikka laskutusdataan, striimattavaan mittausdataan ei käytännössä voi tehdä korjauksia jälkikäteen, mutta siihenkin on mahdollista merkata milloin tieto ei ole luotettavaa. Näin se ei esimerkiksi sotke ML-mallien uudelleenkoulutusta. On tärkeää ensin ymmärtää, mitä tiedon laadun parantamiseksi voidaan ja halutaan tehdä, ennen kuin aletaan kehittää prosesseja – ja varsinkin työkaluja asian korjaamiseksi.
Tiedon laadun käsittelyssä Power Platformin mahdollisuudet ovat vielä monin osin hyödyntämättä, ja myös löytämättä. Vaikkakin alusta tarjoaa paljon uusia mahdollisuuksia, on silti hyvä muistaa, että tiedon laadun prosessien digitalisointi vaatii tekniikkaa enemmän uutta tapaa ajatella niihin liittyviä toimintatapoja. Erilaiset tiedon laatuun vaikuttavat prosessit täytyy tunnistaa, jotta niitä voi lähteä automatisoimaan. Digitalisaatio on voimakas työväline, mutta sen saattaminen käytäntöön vaatii selkeää visiota ja tahtoa kehittää tiedonhallinnan prosesseja eteenpäin ohi totutun mukavuusalueen.
Digitalisaatio vaatii laadukasta dataa onnistuakseen.