Marko Oja
Marko helps customers to understand the endless possibilities of technology and to transform innovative ideas into technical solutions. Agile methods and process development are close to his heart.
I don't recall such hype from a single technology during my career that Open AI’s Chat GPT has made. As a regular person, I am just as into that hype as the next person. But for it to revolutionize the data industry. Well, for that we might still have a bit way to go. On that path, however, the Azure Open AI is a hefty step in the right direction. Here is a story of my first impressions trying to utilize the new service offering.
I wanted to do a text analysis that would, instead of just picking up words, use some kind of intelligence to categorize the inputs. I started to think and search for a data set that would be relatable and would make a simple use case. Song lyrics would be perfect, right? How little did I know...
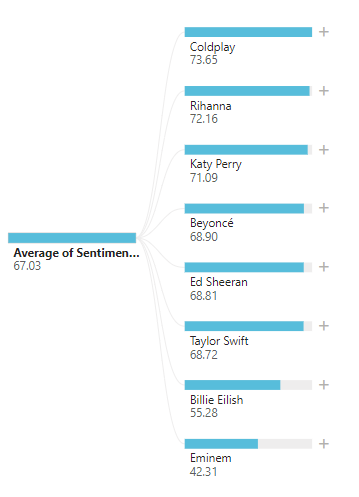 To first describe my use case in few words. I set my goal to get out a numerical ranking for songs in terms of their positivity and make the AI to describe each song in few keywords. If you are here, just to see who ranked the highest among the artists, I won’t keep you in a suspense any longer. Here are the results of the base rankings. Each artists value is the average value of their songs got (Amount of positivity in the range of 0 to 100). Keep in mind that my models are anything but tested and validated. So don’t feel bad (or shoot the messenger) if these do not present the reality. Artists were also selected totally randomly. I can claim that I was unbiased as far as developers go. 😉
To first describe my use case in few words. I set my goal to get out a numerical ranking for songs in terms of their positivity and make the AI to describe each song in few keywords. If you are here, just to see who ranked the highest among the artists, I won’t keep you in a suspense any longer. Here are the results of the base rankings. Each artists value is the average value of their songs got (Amount of positivity in the range of 0 to 100). Keep in mind that my models are anything but tested and validated. So don’t feel bad (or shoot the messenger) if these do not present the reality. Artists were also selected totally randomly. I can claim that I was unbiased as far as developers go. 😉
If you are interested to see more detailed results and the findings of using Azure Open AI with Databricks from a perspective of a data engineering then bravely head on.
Azure Open AI Studio - Playing for business
I haven't really played with Azure ML studio in general for multiple years now. So, something that I found new and wonderful might be a very basic feature. One of these is the user interface, GPT-3 Playground in Azure Open AI Studio, where you can test out the different AI models with text prompts. I found this quite intuitive to use. I just started to play around with the different examples provided (Summarize Text, Classify Text, Parse Unstructured Data, and Classification) and ended up with reasonably well-formed results. If you have played around with ChatGPT, the user experience is quite similar, just a few optional options richer.
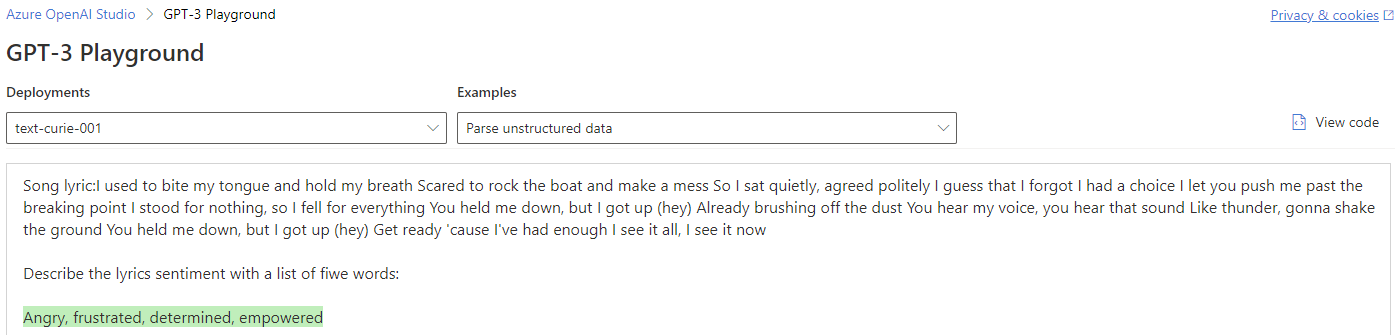
After, an undisclosed amount of time, just playing around with the prompts and examples, I started to check out the other menu options. There is a possibility to make multiple models available for prompting. The UI also suggests the user to use the “best” model for the specific use case. Under models, there is the option to provide also your own data, but as I was more interested in the engineering part of using an Open AI model in a data platform context, so I didn’t immerse myself in the fine details of model tuning. Rather I wanted just to use the out-of-the-box models available to me. I checked the options though and storing fine-tuning data to Azure storage seemed quite straightforward.
After the honeymoon period, I started to build my actual prompts for the AI. Something that I could run with code and get usable results back. It took some trial-and-error efforts to get what I was after. If I had a use case where I fished to receive back a random unstructured text like "summarize this text to me", things would have been a lot easier. But finding a question that provided a standard result was a bit problematic. However, I did not find this issue out at this point. Only after I started to generate multiple results with code, did I realize the need to fine-tune my questions.
There are multiple models in the GPT family check out the website for more details (https://learn.microsoft.com/en-us/azure/cognitive-services/openai/concepts/models#gpt-3-models). I didn't have a change to try to play around with many of the models, as I was more interested in the data engineering side of using the models. There are a lot of things to dig up and test out here.
As first impressions go, things seemed quite simple and intuitive. My inputs were correctly categorized and evaluated. I would say that the user experience is something that will be well-suited for tech-savvy business users to get started on their own. When the grand idea is ready, then it pays out to bring the developers along to finalize the prompt and at the same time remain true to the needs of the use case. There is a lot to consider in terms of technical usability, the randomness of the results, and fine-tuning the models.
One more thing, I wasn’t able to check out yet, was the deployment model. So, at this point, I am not familiar with how the deployment model would work or if it is still under development (This is something I need to circle back to in the future).
From the playground to the factory – Azure Open AI in Databricks
Now, I must give my thanks to the person or team whose responsibility it has been to make the examples and instructions for Azure Open AI usage. Very well done! Hat’s off to you. *Me bowing virtually* 🙏
So, I promised not a lot of code so I’ll try to keep this short. For the basic usage installation, you only need to “pip install openai”. For a bit more production-ready use cases (batches) we need to install a maven library as well. My code for the majority of parts is so close to the examples provided by Microsoft that I will not share them. Only part that I didn’t find was how to dismantle the batch results into a standard table format. So here is that little bit of a code if you want to give it a spin.
When running the result generation in batches you receive this kind of structure in a data frame. Naturally, you want these to be individual rows instead of arrays in the columns.

Here is the “magic” pyspark code to get it formatted correctly for my data:
df = completed_df.selectExpr("explode(arrays_zip(Artist, Title, Year, completions['choices'])) as tmp")\
.selectExpr("tmp.Artist as Artist",
"tmp.Title as Title",
"tmp.Year as Year",
"tmp.choices['text'] AS ResultText")
Both single request and batch requests were both super simple to use, as long as you find out how the prompt needs to be formatted. I would suspect that the models will be getting better at providing the responses in more standardized formats, like json-arrays. I tried to do this, but a considerable portion of the results was still returned in a format of comma-separated string, among other formats. So even though the calling of the Open AI API was simple, there was quite a lot of data engineering that was needed to make the results usable for analytics.
Be a good little AI and eat your data – Open AI API restrictions
With the first simple tests, I did quite well. Posted a few song lyrics and got back good results. But then I stumbled into some issues. First of these was the length of the text I was trying to get the AI to process. There are limits to the length of the queries we can make. There is a “token limit” of 2048 with the model I used. How tokens are calculated is a whole other question. Let’s just say that there comes a point where you need to limit the input length. As expected, short text analysis performs better in terms of requests processed per minute than long ones. And fewer tokens mean smaller costs. I was a bit worried about generating a huge bill for our shared Azure subscription, so I decided to just take a substring of the lyrics instead of trying to use them as whole. The results seemed to be good enough and I was happy.
Post comment: I did my testing with a few thousand rows, but still generated a hundred euros worth of billing, so my concerns were valid enough. Be aware of this if you are planning to do testing with large data sets. Fortunately, I found the pricing to be quite clear, so you can actually calculate and optimize in advance. But it seems that we must wait a bit for this model to be viable for larger data set costs. There are some considerable more affordable models available however, so all is not lost. Here are some additional information about the limits and pricing if you are interested.
https://learn.microsoft.com/en-us/azure/cognitive-services/openai/quotas-limits
https://learn.microsoft.com/en-us/azure/cognitive-services/openai/how-to/manage-costs
https://platform.openai.com/docs/models/codex
The second challenge was with the content of my data. I received the following error for multiple batches: "The response was filtered due to the prompt triggering Azure OpenAI’s content management policy". Now I can't be sure why this happened, but I suspect that the lyrics contained some profanities as the API seemed to reject some Artists more than others. Not sure why inappropriate words or at least prompts are not just filtered out instead of rejecting the whole batch. It would be a major engineering challenge to filter out the unworthy inputs and/or to clean them. API to filter all restricted words from the input would be super useful, or even better a parameter in the current API call to do this. I lowered my batch size to limit the problem, but still ended up with 1/3 of the data being dropped.
The prompts that I ended up using were these:
Super much fun with the results
Not surprisingly Eminem ranked lowest and word descriptions for his songs contained the most aggressive words. Funnily enough, the most common word AI used to describe Eminem’s lyrics was Eminem. Talking about being a phenomenon.
Taylor Swift had a lot of songs in the source material and it throws the overall scores a bit, but single Artist results are quite good. I was quite surprised that Taylor Swift didn’t rank higher. Never listen to her songs but I had an impression of them being very positive.
In total it's easy to find new insight with natural language models. Now Azure OpenAI service has made it even easier than before. It will be interesting times to see how these models will evolve. I can see on the other hand that a chat bot like models have a larger audience, yet from data professional perspective I am looking forward to see models being used for actual data processing. This needs far more standardization and stable results than many other use cases.
Short video of the analysis. I was quite happy of the level of information I was able to squeeze out the results.
Conclusion
Please feel to free leave any comments, I am especially curious about how you see the results. Are they maybe biased? Found something interesting yet intuitively correct? You can find me at LinkedIn.