Marko Oja
Marko helps customers to understand the endless possibilities of technology and to transform innovative ideas into technical solutions. Agile methods and process development are close to his heart.
In a previous blog post I talked about how Databricks Data Lakehouse can be created with low code implementation only. That is almost true. System needs to be setup and for that initial configuration some code is needed. What this code does is it creates a mount to storage account that will be used as storage for delta tables. Fortunately this code is well documented and there are multiple guides to accomplish this like this one: https://docs.databricks.com/data/data-sources/azure/adls-gen2/azure-datalake-gen2-sp-access.html
On high level architecture pattern is simple. Source data is loaded from a file into staging table. View holds transformation rules for the data. And “data mart layer” table is updated with merge statement.
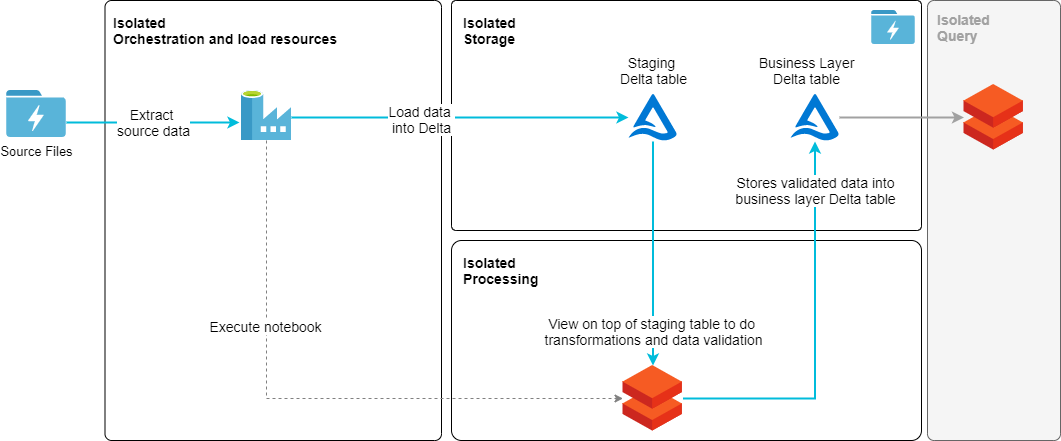
Steps in this load pattern goes like this:

Result is that data is loaded into Delta tables.
Databricks setup needed small code batch but fortunately rest of the implementation is SQL and Data Factory implementation. Before going into the pipeline creation let’s first take a look what we need to setup into Databricks. I had three tables on my setup, but I will share just one to make this easier to follow. First, we need to establish the actual Delta tables likes this:
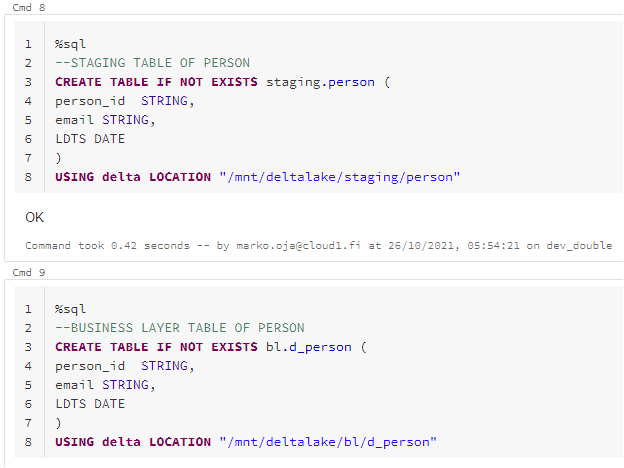
Here I have created staging and bl tables for person.
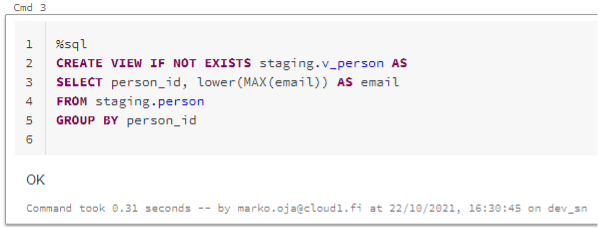
On top of the staging table there is a view to validate I don’t have duplicate ID’s.
And finally, I have the load pattern to load the data into the actual dimension table.
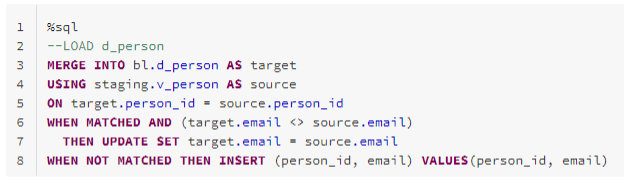
That is all we need to do in Databricks. Rest of the implementation is Data Factory based.
I first created a metadata operated dynamic pipeline but when writing this blog, it got a bit hard to follow. So here is a simplified version without all the bells and whistles. Basic load pattern with dedicated copy activities for each table and notebook execution to run merge statements.

Source for copy activities is a basic azure blob storage and sink is Azure Databricks Delta Lake dataset. Both uses parameter to specify target file or table. To use Delta Lake dataset a running interactive cluster is needed which is configured in a linked service just like it would be for a basic notebook execution.
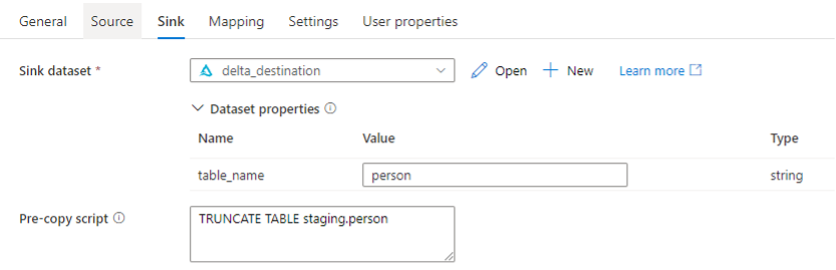
The copy activity itself doesn’t hold any magic. There is possibility to run a Pre-copy script like in SQL databases. Here truncate is used for staging tables. But also, more Databricks specific commands like VACUUM could be used to optimize loads further.
The notebook calls at the end of the pipeline does nothing but executes my notebook containing merge statements in Databricks.
The entire pattern was extremely simple and straightforward. As a low-code implementations should be. I had the most low-level cluster with single node setup on Databricks. Needless to say load times were not impressive. I believe that there would be much better suited patterns to use for Databricks even written with SQL that would perform much better than the ones I used. This pattern was however straight from traditional data warehousing implementation, and I was determined to test just that.
For keeping raw data history, Delta Lake seems very promising. In real-life scenario the load pattern would be naturally a bit more complex. Also, for Data Factory implementation more dynamic metadata operated solution would be preferable. Still, this is a very close to real life scenario requiring only small changes and it is a low-code solution and quite cost effective one. Delta lake is a promising tool in the modern data platform toolset, and I expect to see growing amount of implementations utilising it in the future.