Marko Oja
Marko helps customers to understand the endless possibilities of technology and to transform innovative ideas into technical solutions. Agile methods and process development are close to his heart.
So, here’s the deal. One weekend I found myself stuck at home in Covid quarantine waiting for the test results for my kid. Instead of watching the TV the entire Sunday, I decided I might try to use my time doing something a bit more productive.
The quiet, unsexy parts for data development, such as modelling and data issues, have always been close to my heart. Fortunately, times evolve and today data quality seems to be among the top discussion topics in the industry. I started investigating and researching data quality more broadly roughly a year ago for a series of blog posts I was writing. In my company we have also raised the theme as one of the key interest areas of the current year, which has led us to look for good candidates for a data quality framework. One of the more promising ones is Great Expectations, greatexpectations.io.
That’s my task for the day. I’m not really trying to write an instructions manual for installing and implementing DQ rules, but rather marking down the feelings and considerations popping up as I go forward. I hope you enjoy reading this as much as I enjoyed writing it. 😊
I have no previous knowledge of Great Expectations other than the few articles I have read on their web page. I start by simply creating an empty resource group to my Azure Subscription and a Databricks workspace to work with. I do have a dataset that I have created for DQ testing and will be using that. The dataset consists of a small batch of data in three csv-files.
I am in such a lucky position that I’m able to use Terraform for creating my resources. I even have the possibility to use my company’s templates to do so. That makes creating the Databricks workspace, Spark cluster and storage account easy. In no time I have created the storage for the Terraform state file and Terraform initialization is ready. Firing up resources! Just testing the IAC code first to make sure it won’t remove anything important such as the resource group. 😊

So far so good. Next, I apply my resources and then just wait for Terraform to do the work.

It takes a while for these resources to be created, which gives me a moment to read about how to install Great Expectations. What I found was multiple pages and a-not-so-shallow rabbit hole. I would really like to install the python package on my cluster and that’s what I’ll try. But let me first check if my environment is ready!
They say life is a series of failures leading to a success. I noticed my naming conventions were off, meaning I need to recreate the resources with proper naming. The good thing is that my script worked from all other aspects as expected and I am confident that after a re-applying resources I will be good to go. Sometimes I feel nostalgic for the times when the world was simpler and testing a new thing meant just making it work on my own laptop. Having said that, I do appreciate the easiness of whipping up a production equivalent environment from the scratch in just a few hours. Having an environment for testing with a similar setup and identical configurations to production environment is no small thing. Unfortunately, I find this way of working is not as common as I would like it to be in the data development circles.
My resources are finally ready, and I can start my research work. At this point I know that I need to install the library either in the cluster initialization or through a notebook. My plan is to try add the python package manually to my cluster and then install it using terraform. This is just to minimize the manual steps in case I need to repeat the installation in another environment. This is the likely scenario if the tool proves suitable for the task.
All good to go and I seem to have guessed correctly how to add the library to my cluster without importing it back from Azure. I couldn’t have asked for more.
Validating installation.
So far things are looking promising. At this point I am referring to a “Getting started with Great Expectations” tutorial. According to the guide I need to “initialize a data context”. Having no idea what that means I need to do some more reading. After all, I don’t just want to follow a tutorial but to do my own proof-of-concept testing. As I read on, I find out that “Data Context manages your project configuration”. It seems to be a kind of configuration or representation of a project. What it does and where it exists, I have no idea of at this point. As the creation of data context doesn’t take any parameters I will just push on and see when I hit the wall.
After some more searching I had to give up as the documentation I had found was missing instructions for Azure. A lot of times I ended up on a page with the text “This article is a stub”. After an hour or so of googling I managed to find a notebook example that should work for me. What’s ironic is that I found it on the Databricks documentation site and not on the Great Expectations page. Funny enough, that’s where I also found a link back to the Great Expectations page with a more comprehensive notebook example. That’s exactly what I was looking for! Now, let me try to summarize what my problem was in terms of not getting it right the first time.
Great Expectations (GE from now on) has its own philosophy for how to do things. You start by defining a Data Context, which I understand as something like a project. Then you move on to set up data sources and finally the rules you want to use for evaluating the data quality. However, my goal was to investigate whether GE can be used as a module for existing code or pipeline. I don’t want to define data sources for GE as I don’t know where my data will be. Besides I don’t think it’s for GE to keep track of the that. All I know is that my data will be presented as a data frame in Python, and it is against this data frame that I wish to execute validation rules. Finding instructions for this wasn’t as easy as I would have expected. What I don’t really get yet is why GE wants to be informed of the data sources. It might have something to do with result documentation.
And down the rabbit hole I go again! After an hour of testing and finding out what works and what doesn’t, things that first seemed to work but, in the end, didn’t, I finally hit a hard wall. My configuration was not okay. I had no idea why that is so I start to break the code in to bits and pieces. I found the simplest way of calling GE methods directly for my data frame. Here it is:
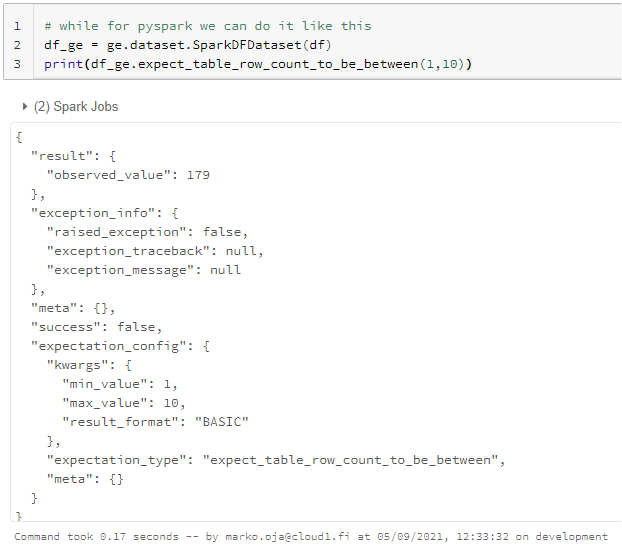
My first evaluation with GE framework is done. In a nutshell, I “convert” spark data frame into a GE spark data set and call for a validation method. Seems easy enough. My next task is to explore the out-of-the-box methods GE comes with and do some testing with them.
GE looks quite promising to be honest. There are fifty-ish out-of-the-box methods with possibility to create my own ones. First method that caught my eye was the regular expression method. I had planned a test with regex: product_id should be numbers only with length of 5 (leading zeros).
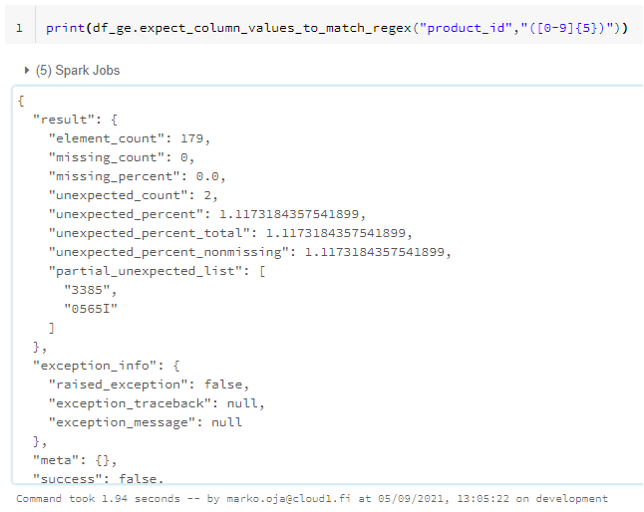
The result gave me two false negatives which is correct for my dataset. I also got a partial_unexpected_list. That’s not exactly what I was hoping though. I need the full list of the rows that do not comply with my rule. The full list is especially important for a dataset like this where all the rows that are not valid should be fixed. At minimum I need to know how many rows the list will hold. Better still if the full list could be easily exported elsewhere.
I couldn’t find out if there is an “official” way of storing the invalid results but at least there seems to be an unofficial way of getting the erroneous rows out. When using the GE suite I can define the result format to be “complete”. Then the validation returns the full set of unexpected values. However, this works well only when I filter my original data with the set of unexpected values. As an example, testing for invalid ID’s this seems to work rather well.
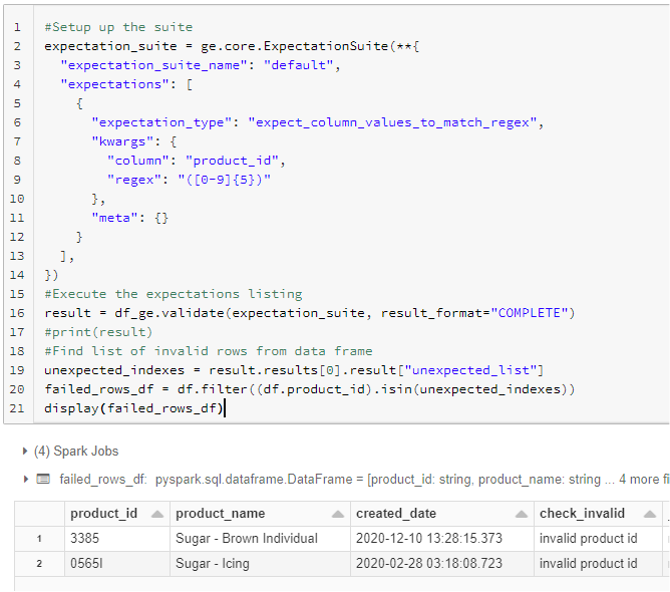
Note the “check_invalid”-column. It’s an original attribute (and not a result) of the data set to help validate any results returned by the evaluated solution.
More importantly, I learned to use the framework in a way that is at least somewhat closer to how it was meant to be used. Instead of just force calling the methods I can define an entire set of rules and parameters and use that to execute the validations. Setting up this syntax in a configuration file would be highly practical and I’m beginning to see the benefits of the framework. Binding it to an existing data pipeline and architecture, however, isn’t exactly a plug-and-play job.
So, what was I left with? First off, there seems to be a bunch of usable functionalities here. However, the need to combine transformation logic from a basic data frame into something that GE can use looks a bit clumsy. Second, the instructions are missing, especially for Databricks/Spark. I do realize that I am not a hard-core Python (or any other kind) coder and would I have deeper Python knowledge things might have been easier. That being said, any product or system that’s intended to be adapted widely must have damn good documentation available. In my opinion that’s not quite the case with Great Expectations at this point, but I have also seen much worse.
I really need to do more research and maybe try the official way to grasp the usefulness of some of the parts I neglected systematically during this first phase. I’ll probably need to ask for coding instructions in order to create some custom rules and see what restrictions, if any, those have.
Great Expectations has some cool features including data profiling and automatic documentation. I don’t think it be too hard to support a fixed set of rules to be configured through UI. As of now, it should also be relatively easy to fit this code into a pipeline with a few modifications and capsuling. All in all, the framework seems promising and would surely be worth a deeper investigation. I’m looking forward to having some time to do just that.
My kid’s covid test came back negative. All is good and we didn’t have to stay indoors for more than a day. 😊