Marko Oja
Marko helps customers to understand the endless possibilities of technology and to transform innovative ideas into technical solutions. Agile methods and process development are close to his heart.
There are many different services on Azure that are used for IIoT solutions. Playfully I call this versatile stack as a jungle. And why not. We can see few different layers there from usage and also from architectural perspective. But before we go into details let’s take a step back to see the forest from the trees so to speak.
Download our blueprint about IIoT.
To recap on what is IIoT and for what it is used for, let me give few examples of use cases from industry point of view rather than in general possibilities that are more ordinarily used.
1. Factory automation systems are one of the most common sources that I have been working with and discussing with customers. Now it varies if an automation system is factory wide, dedicated for a production line or some smaller production unit. However from a data gathering point of view these are usually seen as one IIoT “device” that produces vast amount of measurement points, tags or series, which ever we want to call them. So these differs from the commonly known IoT-devices from the perspective of producing a lot more data per device. This also means that adding context to this data like a name and description will be more often done on individual measurement level rather than on device level.
2. Vehicles (or any moving machinery) are also quite common IIoT measurements source. Not every business have them but nevertheless they are quite common. They have at least one distinct feature and that is a geographic location. Longitude and latitude are common parameters but for many IIoT cases they are just a static property instead of telemetry. Other thing that comes across quite often on these vehicle type sources is measurements of acceleration on different axis. Metadata for vehicles is usually linked directly to devices which corresponds to individual vehicles. But instead of having only static properties they also often link to data like work schedules. Meaning that we also want to know which person should be linked to this data at any given time.
3. Third example I wanted to bring up is singular IIoT devices. Now these are from the category what commonly is first thought when we start to speak of IIoT. Usually there is a device or rather a product that can be sold and deployed to a customer. It is registered to a specific user (usually customer or a partner company) and it does a specific task. Use cases can vary from a simple thermometer IoT device to a single product producing multiple different measurements. These kind of products main goal might also not only to be a measurement device but rather the data collected is about the devices usage and state. To give a real life example from news I have seen I could at least think cranes and welding machines, which have an IIoT aspect to them but where the main functionality is something totally different.
These are just few example what kind of sources are out there. I wanted to give some perspective on how versatile use cases are and because of that data enrichment, transformation and usage requirement varies quite a lot. This is important to grasp because the diversity of an ecosystem is a major factor when selecting a suitable architecture.
So now, if we have created a system or device that is producing a real time IIoT stream, what to do with it? From technical perspective here’s the problem: We have multiple different technical options basically to do the same thing. Let’s try to categorize these a bit before it gets too problematic. First of all, on Azure there are two main services that can be used to connect an IoT stream from streaming source to the cloud. These are IoT Hub and Event Hub. IoT hub is a more sophisticated version with lots of different features and Event Hub is a simpler work horse. So when you have an use case where for example you need to feedback a data to the device or support a specific IIoT protocol then you will most probably decide to use IoT Hub. When you are planning to have hundreds or thousands individual devices then you might want to use Event hub. Also there are needs when you need to buffer data inside your platform and Event Hub comes with a smaller price tag for such use cases.
Second layer of technologies where the real problem of selection lies are the data ingestion and processing services. I will only mention about Stream Analytics and Azure Digital Twins as either of them doesn’t really fit the spot entirely. You can think of these as additional services that you can use if needed, depending on technical and business needs and selected base services. I encourage everyone to see the basics of those to find if they can be useful for your needs.
The three services I wanted to bring up however are Time Series Insight, Azure Data Explorer and Databricks (or Synapse Spark as same perspective applies). We have already seen each of these being used for stream handling but even for a technical person working on this field it is sometimes quite difficult to grasp what different use cases each of these solution should be used for. I am not a right person either to elaborate this completely as there are lot of edge cases but I have found a mindset that at least helps me to roughly assess if the service might be suitable for a given situation. That is the ease of use or the same thing from slightly different perspective: the maturity of predefined usage model a service provides.
Let’s start with the most out of the box ready solution: Time Series Insight. At first it is good to point out that TSI actually uses Data Explorer as a “warm storage”. Meaning that it keeps most recent data readily available to be able to produce extremely fast query responses.
First place you can see the nature of TSI comes pretty early on the implementation phase. When setting up the environment (adding Azure service) you need to define a series id-property for all of your data and this cannot be changed afterwards.
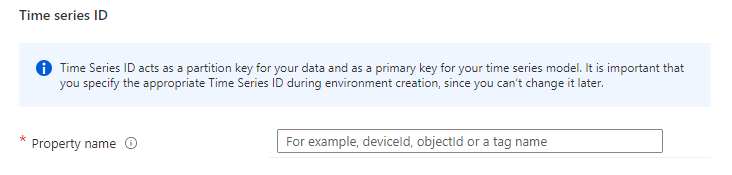
This might at first seem like a huge problem but adding a simple processing engine like Stream Analytics or Azure Function between TSI and IoT / Event hub can mitigate this problem quite a lot. However this is the first indication of selecting an out of the box ready solution. It is meant for time series data. It is easy to use and very powerful for that use case. But it lacks on versatility.
Now setting up a stream ingestion is an ease, once you get the hang of it. I used my laptop memory, swap, disk and CPU usage as an IoT device to provide some example data. The only a bit tricky part is to find the correct schema configuration for you data. Sometimes data just is not what it supposed to be, but fortunately TSI do provide some scripting options to fix small transformations issues. To give this some more context, here is a payload I sent from my laptop as a single stream batch. It includes 4 events divided to separate type of measurement:

And here is how it needs to be setup:
Note that I used string values in JSON payload, just to proof that simple transformations can actually be done. Definitely not meant as a best practice to follow. 😅
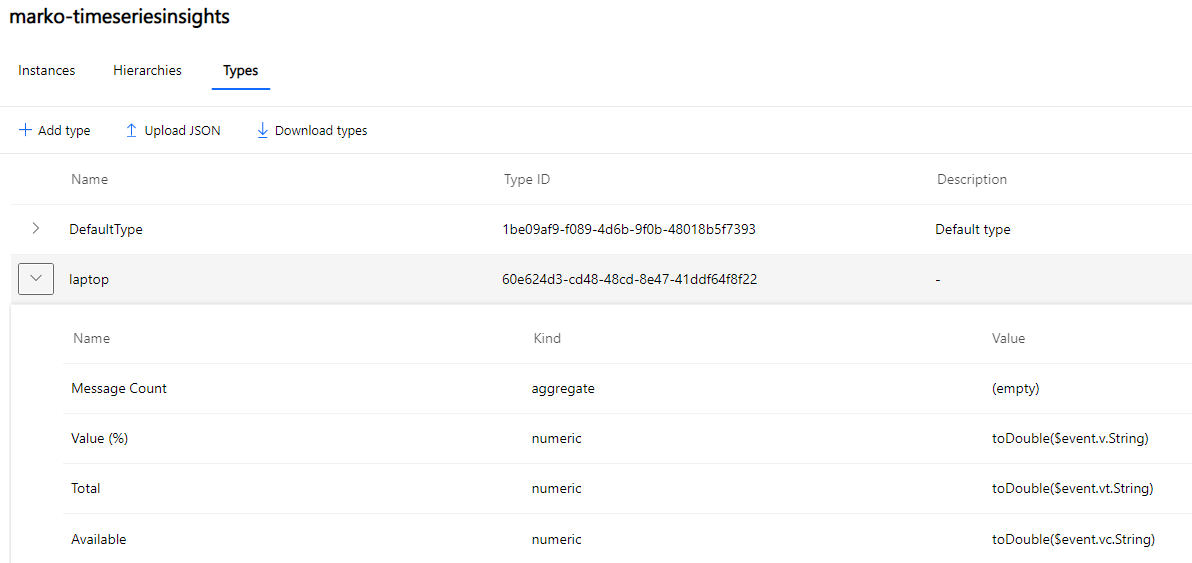
Now if you haven’t done much design work on IIoT data, then it is a bonus that TSI provides a valid structure to put your data into. It has types that basically defines where in the payload a value can be found and how to transform it into a usable attribute. TSI also has instances-part that basically are your measurements or devices, how ever you wish to set up and define granularity. Then there are hierarchies that can be used to group your data to a meaningful groups like having single factory’s data in one hierarchy with different production units, lines and phases. All and all a very useful metadata structure when applied correctly.
Then there is the analysis part and here (mostly perhaps because of my long experience on the subject) I feel the most struggle. Let me start pointing out that the graph provided here looks really really cool. Good job UI team!
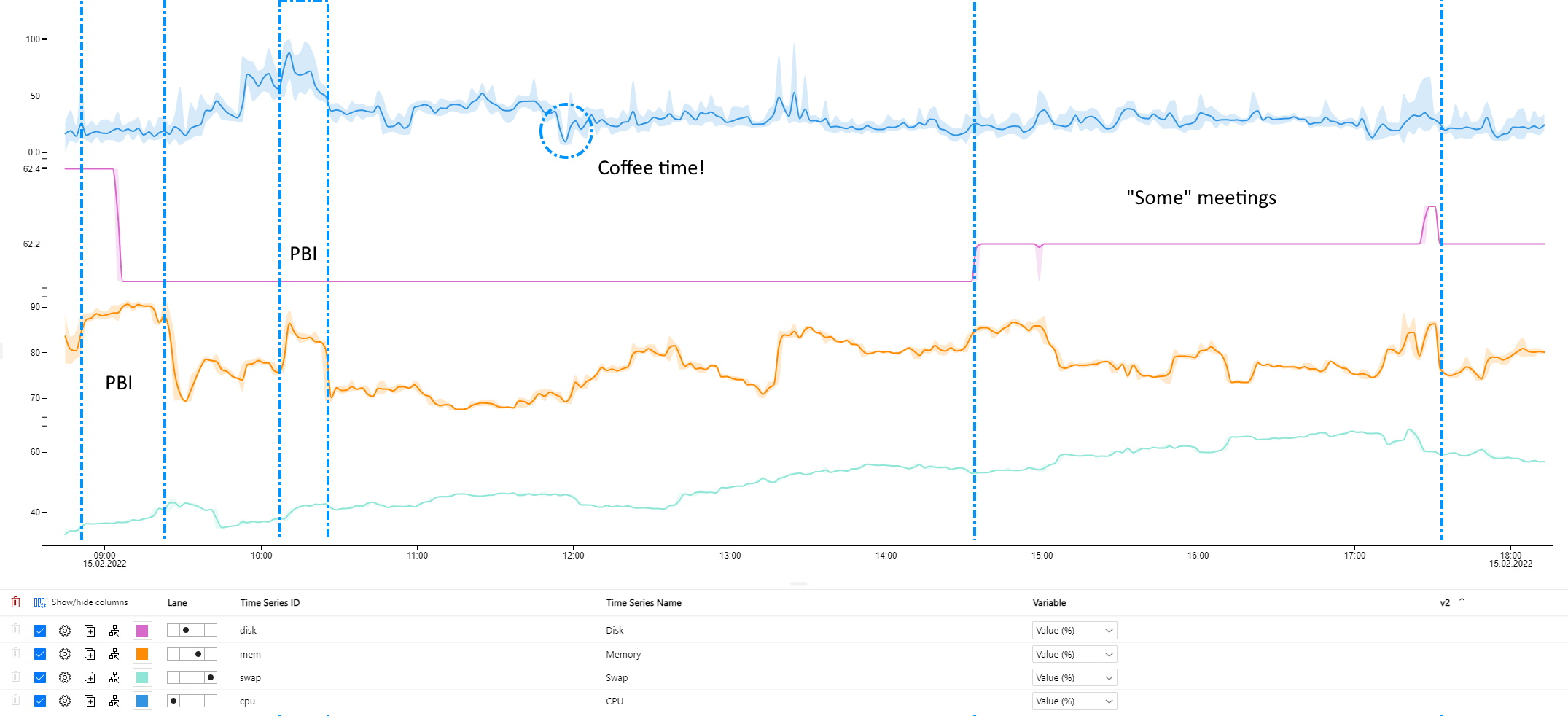
This is actually my single “work day” in a graph format (Blue lines and text are added by me to provide a bit of a context. 😊). The first “jump on orange (CPU) graph is about me presenting Power BI report to my colleague. And then presenting the same thing an hour later. The report allows you to zoom in and even view your raw data. Absolutely an useful features and for some use cases might do the job brilliantly. You can also bring this data to Power BI and that is a very important feature in my opinion, but unfortunately the way you can add it is quite restricted. There are APIs for application usage but let’s face it: custom applications shouldn’t be a go to tool these days for analytics. The static way a query is set up and not having direct query option are annoyingly inconvenient shortcomings. If your solution is more static, like backend for existing application, then this might not be any concern for you.
In a nutshell TSI provides bunch of important stream handling core features and a sturdy backbone architecture with a way of guiding an IIoT data management thinking into a right direction. Even if you don’t end up using it for your solution, you should still definitely be aware of the mindset it presents because there are much to learn from it.
The middle ground is the Data Explorer. DE is not meant only for streaming data but basically for all event based data or even for all big data use cases. And because of this it has way more flexible data structures as well. The down side of course is that it doesn’t really provide any out of the box structure for you data processes like TSI does. Not that it is always a bad thing to be able to build your own way. I am all for it. But it does require a bit more tweaking to do to get your stream ingested, but no worries it’s not overly complicated.
You need to create a table and a mapping for the table to ingest a payload. Then just establish a connection. Currently there are two ways about doing this manually. One is through the Azure management portal and it is a bit more manual where the other is wizard based through DE’s own UI.
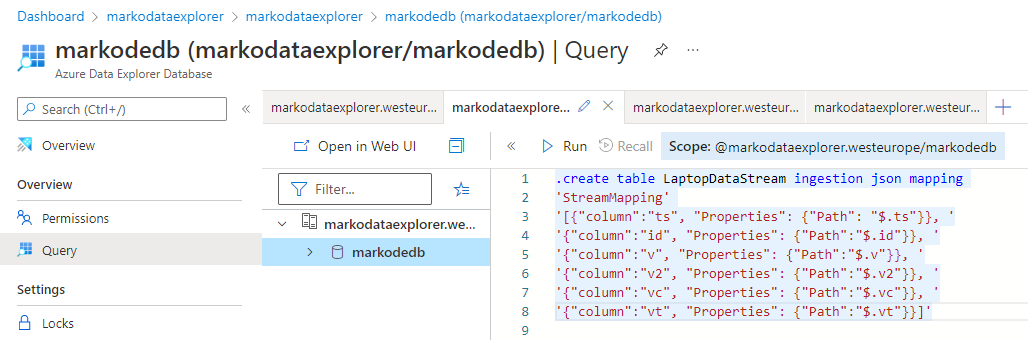
For a while, Data Explorer is only supported Kusto as a query language. While I am a quite a accustomed with Kusto-language because of Azure Log Analytics, I wouldn’t choose it to be my primary query language for querying stream data. It’s a matter of an opinion if the syntax really is useful for an actual data analysis but what is fact is that way more people, including end users, are way more custom with SQL syntax. Now the good news is that Data Explorer finally also support SQL queries. Also what makes it even more usable from an analytics point of view is the support by Power BI. More specifically it supports both direct query (data queried directly in real time) and import modes (data ingestion scheduled to Power BI Data model). DE also provides its own dashboards but to be honest with these kind of solutions I always feels like I am trying to work both arms and legs tied up and wriggle like a worm forwards to my goal. They are more of a bonus feature but a true support for an analytical tool is an actual major feature, in my humble opinion.
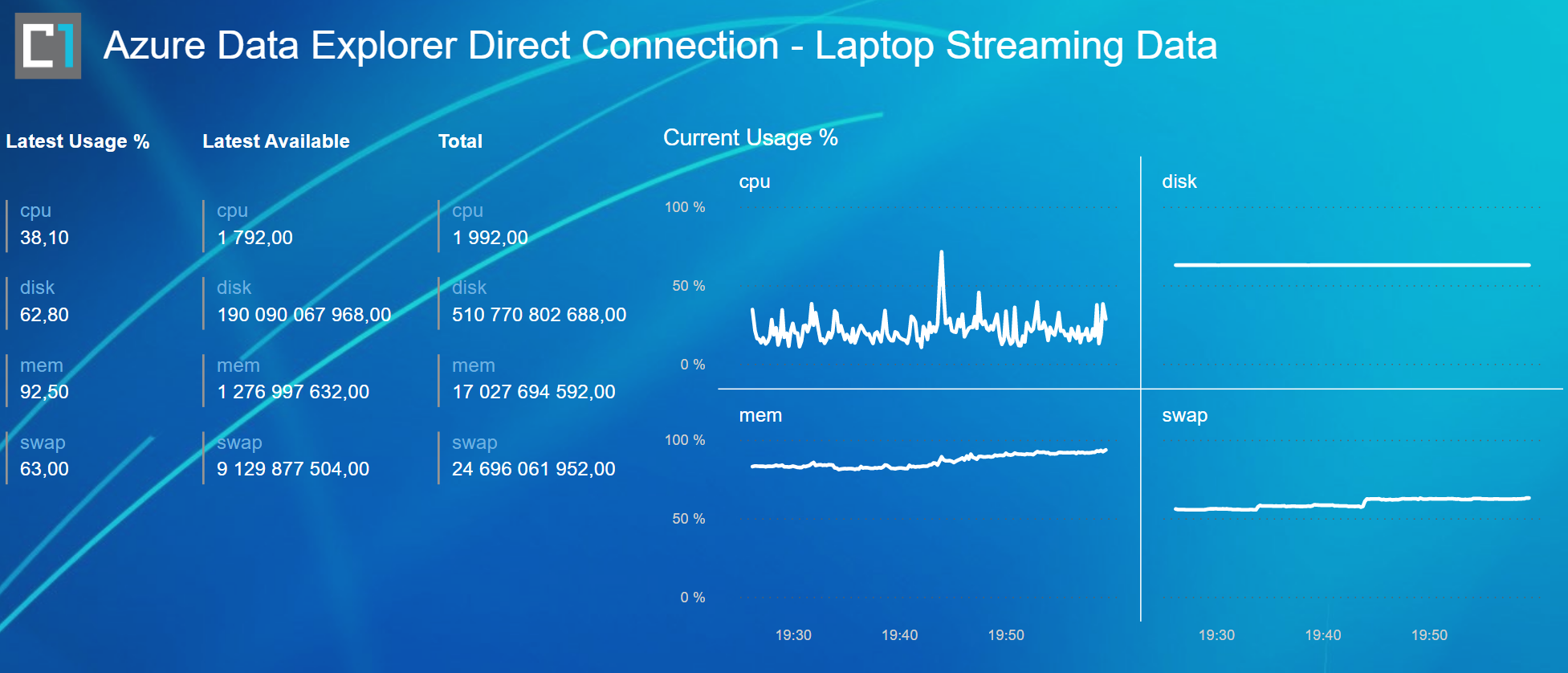
Considered that it took me a 15 minutes to create this report and I can easily manipulate almost any part of it. It is a huge leap from more or less limited out of the box dashboards. With new Power BI features like composite models I can also easily enhance this real time data model with data from external sources without any extra work on the backend.
Too good to be true though? Well yes. There are shortcomings with the Data Explorer as well. Like it is the case on some level with all the not “built from scratch”-solutions. The control of sources and targets, stream handling edge cases, advanced analytic use cases and general controllability like for example stream dedicated cluster setups are not at least easily possible with DE. You can of course always add an extra frosting with other services like Databricks, but then why wouldn’t you do it all with a custom solution? Well having parts of your basic stream handling come out of the box might be a good option especially if you don’t have previous knowledge of IIoT implementations or generally lack needed development resources. Enabling stream ingestion with DE don’t require any coding. Also giving that one part of management to Microsoft can help you avoid few nasty pot holes on the way.
Well, I am not going to go into details of Databricks IoT stream implementations. Let’s just say that getting started with stream processing itself is not overly complicated, if you are familiar with Databricks in general. However if Databricks or Spark is not a familiar tool for you or to the development team, then the knowledge gap can be an obstacle. Basic Stream ingestion code itself resembles something like this.

Not too many rows of code. And results can be viewed as chart or as raw data table.
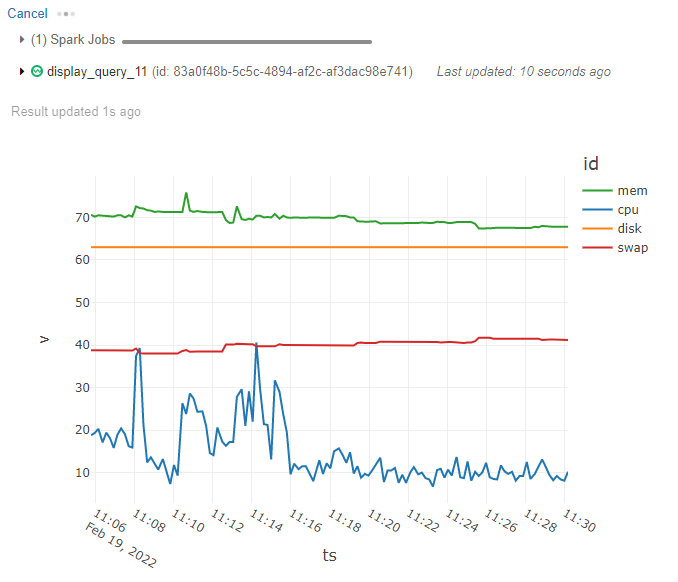
Naturally, if you store the streaming data into a storage, let’s say for example using delta tables as the target. Then you will get the full spark SQL interface and data analysis options, like with any other data. Providing this data through Databricks SQL endpoints and adding access control layer in the process can be generalized and end users can access it like any other data through a single service.
Now with this way of implementation you also get full control of basically everything. You can tackle VERY custom payloads, define targets (yes you can easily have multiple) and even specify the cluster setup dedicated just for the one highly business critical stream or run all streams on a shared cluster. Continuous deployment models are also standard as far as it comes to Databricks and IoT / Event Hubs. Meaning that you don’t have to build additional pipelines or add additional monitoring etc. into your platform for Streams if you already are using Databricks for something else. There are definitely benefits of using one tool that can handle all your cases and needs, versus using a stack of multiple tools.
So what to choose?
It’s not an awfully bad idea to make a lab environment to test out a wanted setup whichever way you might decide to go. I will even go to such lengths that I will highly recommend this approach. Test it small and develop actual production environment separate.
Now when it comes to first deciding what you should start to test out I would follow this line of thoughts:
Each of these tools have their strengths and weaknesses and not one is ultimately better than the other. At least not from an end result perspective. One can challenge this from technical performance, service cost, data management or [take your pick] perspective. And true enough many of these will be valid points. How ever the true cost of a system comes from the initial and future development efforts, the delay to get data in use (time to market) and potential production and management challenges. These always needs to be carefully weighted when building an IoT solution and not just picking up the tool which seems to be the coolest at the time.
I hope this little stroll through the Azure IoT jungle gave you some ideas or views about the current selection that is available out there. I at least am eager to see these products evolve even further and become more widely adapted. From a developer perspective IIoT data is quite interesting and provides a new challenges as well as endless usage opportunities.